Локальные нейронные сети
Оглавление
Оглавление
- Нейронные сети на ПК
- Програмное обеспечение
- Llama-CPP
- msty app
- Jan for Desktop
- open-webui
- AnythingLLM
- LM Studio
- Appimage extract
- Text-Generation-Webui
- Miniconda3
- TavernAI для Text-Generation-Webui
- Stable-Diffusion-Webui
- one-click-installers
- KoboldAI или KoboldAI GIT
- Krita
- Krita AI Diffusion
- SubTitleEdit
- stabilityai/stable-diffusion-3.5-large-turbo
- Image Creator
- Stability Matrix
- DALL·E mini
- SillyTavern
- KoboldCpp
- Axolotl
- Backyard AI
- InvokeAI
- Параметры
- VRAM и RAM для запуска модели
- Квантизации и требования к оперативной памяти
- Форматы с плавающими точками
- Архитектура Transformer
- Tokenization и токены
- KV Cache и VRAM
- GGUF, EXL2, GPTQ и AWQ
- llama.cpp и KoboldCpp
- vLLM и production inference
- TabbyAPI и EXL2 RP stack
- SillyTavern и RP ecosystem
- RAG и векторные базы
- LoRA, QLoRA и Fine-Tuning
- CUDA, ROCm и ускорение
- MLA (Multi-head Latent Attention)
- Flash Attention 3
- Модели
- Mykes/medicus, TheBloke/medalpaca-13B-GGUF, TheBloke/med42-70B-GGUF
- gemma3:4b
- codegemma
- codellama
- dolphin-mistral:7b
- dolphin-mixtral
- llava
- falcon
- llama2-uncensored
- reefer/erplegend
- gdisney/neural-chat-uncensored
- reefer/erphermesl3
- jimscard/adult-film-screenwriter-nsfw
- TheBloke/Llama-2-7B-GGUF
- nidum/Nidum-Llama-3.2-3B-Uncensored-GGUF
- saiga2 7b gguf stable-diffusion model
- PygmalionAI
- Другие
- Lora Model
- Gemini
- Claude Haiku
- DeepSeek
- Qwen-Claude-Sonnet
- Mistral-7B-Instruct-v0.3
- Phi-3/Phi-4
- saiga2 7b
- SDXL Turbo и SD 3.5
- Конвертирование моделей
- Запуск GGML/GGUF через ollama
- Программирование
- Загрузка моделей с Hugginface
- Дополнительная информация
- Roleplay модели (с акцентом на русский)
- Введение
- Системный промпт
- MythoMax-L2-13B
- Nous-Hermes-2-Yi-34B
- OpenHermes-2.5-Mistral-7B
- Chronos-Hermes
- Noromaid-Mixtral
- Mag Mell 12B
- Qwen2.5-7B/14B
- Llama 3.1/3.3
- Датасеты на HuggingFace
- Нейронные сети на Android / IOS
- Ollama VPS/VDS
- VPS/VDS n8nio/n8n
- Docker и Self-Hosted AI
- Linux Survival Guide
- AI агенты и automation
- Практические AI стеки
1. Нейронные сети на ПК
Что такое нейросети, модели и квантизация?
- Нейросеть — это математическая модель, вдохновлённая работой мозга, которая состоит из множества взаимосвязанных "нейронов" (узлов). Она обучается на данных, чтобы решать задачи: распознавать изображения, переводить текст, генерировать контент и т.д.
- Модель — это конкретная обученная нейросеть с набором параметров (весов), которые она получила в процессе обучения. Например, модель GPT-2 — это нейросеть, обученная генерировать текст.
- Квантизация — это способ уменьшить размер модели и ускорить её работу, переводя параметры из высокоточных чисел (например, 32-битных float) в более компактные форматы (например, 8-битные int). Это снижает требования к памяти и вычислениям, иногда с небольшой потерей качества, но часто незаметной для пользователя.
Что такое LoRA (Low-Rank Adaptation)?
- LoRA — это метод тонкой настройки (fine-tuning) больших моделей, который позволяет адаптировать модель под новую задачу, обучая лишь небольшую часть параметров, а не всю модель целиком.
- Идея в том, что вместо изменения огромной матрицы весов модели, LoRA добавляет две маленькие матрицы низкого ранга, которые корректируют поведение модели. Это значительно снижает вычислительные затраты и объём данных для обучения, сохраняя при этом высокое качество результата.
- Такой подход особенно полезен для дообучения больших языковых моделей (LLM) и генеративных моделей, когда нет ресурсов для полного переобучения.
1.1. Програмное обеспечение
Далее ниже указан список програмного обеспечения для работы с нейронными сетями.
Нужно понимать, что одни программы предназначены только для работы на Linux, другие только на Windows,т.е. далеко не все могут работать в обеих ОС.
Также есть нюанс касающийся самих программ для работы с теми или иными моделями нейронных сетей - это конкретные задачи, которые нижеуказанные программы могут или не могут выполнять. Один тип программ только для работы с текстом, другие для работы с изображениями, третьи для работы с видео, субтитрами и т.д. и т.п.
Для каждой программы я указываю несколько типов ссылок.
- Ссылка на официальный сайт - обязательна.
- Git https ссылка - Если это Git репозиторий.
- Git ssh ссылка - Для более быстрого скачивания через Git.
- Git Release ссылка - чтобы сразу найти последнюю версию программы.
- И ссылки на сами программы для разных ОС и разных архитектур - i686 (x86), amd64 (x86_64).
Для каждой программы если это не официальный сайт, а конкретно Git репозиторий - внутри каждого есть инструкция по установке и использованию, поэтому добавлять ее сюда и загромождать место не имеет смысла. Информация в этом случае будет дублироваться, а если при обновлении в репозитории хоть что-то изменится - то она даже будет не актуальна.
У меня на Linux - используется пользвотель «Mikl». И для запуска я испольную отдельную папку с иконкой и скриптом запуска просто для удобства.
Нюанс. У меня установлен «Python» и «virtualenvwrapper». Как установить его на Linux или Windows можно посмотреть здесь.
В папке пользователя создана отдельная директория, например «/home/mikl/programs/ollama-apps/».
Еще один нюанс - В Linux я чаще использую «.Appimage» формат введу его универсальности, т.к. он уже содержит в себе все необходимые библиотеки и устанавливать их в систему и думать будут ли они конфликтовать с теми, что там уже есть - мне не приходится.
И еще «.Appimage» архив запуска я обязательно распаковываю в отдельную папку для ускорения работы с программой и также удобства работы с ней, т.к. появляются настройки, которые можно вытащить, скопировать, перенести и т.д. и т.п.
Распаковать «.Appimage» формат запуска можно вот так.
Поясняю нюанс по поводу всех форматов файлов в Linux. В Linux все файлы не важно какого формата по сути текстовые и редактируются, даже если это просто ярлычок запуска с рабочего стола. Удобнее всего использовать «Редактор Geany» для редактирования файлов. Важно только то, где эти файлы располагаются и имеют ли права доступа для запуска. Иногда их просто подключают как начальную точку входа в тот или иной скрипт, а иногда используют просто как информацию, а иногда такой файл бывает полноценным скриптом даже без формата. Если у файла есть права доступа для запуска, то файл является выполняемым, как .bat или .cmd в Windows, только здесь ну нужны никакие форматы.
Например, любой ярлычок запуска на рабочем столе. По сути представляет из себя некий ini-файл в котором указаны параметры его работы и ему даны права доступа для запуска. В Windows не полноценный аналог - простой ярлык на какой-то файл, если посмотреть его свойства правой кнопкой мыши. Не полноценный, потому что в Linux гораздо больше возможностей настроек запуска того или иного ПО. В Windows только указать путь к файлу запуска и корневую директорию.
Также не забудьте установить саму Ollama программу, потому что без неё у вас ни одна другая утилита не заработает.
На указанном официальном сайте есть версия и для Windows, и для Linux.
Для Linux следуйте вот этой инструкции.
Установить новую версию, если программы еще не существует в ОС.
curl -fsSL https://ollama.com/install.sh | sh
А вот обновление Ollama чутка сложнее.
1. Сначала надо Удалить старые библиотеки.
sudo rm -rf /usr/lib/ollama
2. Скачать и распаковать пакет.
curl -fsSL https://ollama.com/download/ollama-linux-amd64.tgz | sudo tar zx -C /usr
3. Запустить Ollama.
ollama serve
4. В другом терминале проверить, что Ollama запущен.
ollama -v
Ну или так.
sudo systemctl status ollama
Если не получается запустить сервис ollama.
sudo systemctl daemon-reload sudo systemctl restart ollama
Нюанс по поводу комманд на Linux.
Если ОС не выполняет команду - выдаёт ошибку, попробуйте добавить в начале команды: «sudo».
Это повысит права доступа до root-а и команду можно будет выполнить принудительно.
Нюанс по поводу Python-а.
Если вам нужен Python, наиболее свежей версии, то скачать его лучше всего с официального сайта.
Если же у вас более старая система, или вы хотите адекватную портативную версию Python-а, то одну из версий можно скачать из моего репозитория python-portable-links.
Если же вы в принципе не умеете работать с Python-ом - прочитайте хотя бы «базовое руководство по виртуальным окружениям, а также установке и запуску портативных версий их преимуществ».
Официальный сайт Ollama.
Python версия Llama-CPP
Llama-CPP — минималистичный open-source движок для запуска больших языковых моделей (LLM) на CPU и GPU с поддержкой web-интерфейса и API.
Установка и запуск. Это Python версия, с ней можно работать через Python и виртуальное окружение. Это нормальная практика.
git clone https://github.com/ggerganov/llama.cpp.git pip install -r llama.cpp/requirements.txt python llama.cpp/convert.py -h python llama.cpp/convert.py vicuna-hf \ --outfile vicuna-13b-v1.5.gguf \ --outtype q8_0 # --outtype f16 # --outtype f32 # --outtype bf16
Установка на Linux и использование.
$ ollama show your-model-exist:latest --modelfile > Modelfile
$ nano Modelfile # Example
# FROM Model-Name
FROM /YOUR/PATH/Local-Models/Model-Name.ext-model
TEMPLATE "<|im_start|>system
{{ .System }}<|im_end|>
<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
"
SYSTEM You are my-own-model, a helpful AI assistant.
PARAMETER stop <|im_start|>
PARAMETER stop <|im_end|>
$ ollama create my-own-model -f Modelfile
$ ollama run my-own-model
Приложение msty app
msty app — приложение для работы с локальными языковыми моделями с удобным интерфейсом и поддержкой различных форматов моделей.
- msty-x64 windows gpu (amd or nvidia)
- msty-x64 windows cpy only
- msty-x64 linux nvidia AppImage
- msty-x64 linux nvidia DEB
- msty-x64 linux amd gpu -rocm AppImage
- msty-x64 linux amd gpu -rocm DEB
Приложение Jan for Desktop
Jan for Desktop — локальный AI-ассистент с возможностью работы с языковыми моделями и интеграцией в рабочий процесс.
Использование open-webui.
open-webui — веб-интерфейс для запуска и управления локальными языковыми моделями на Linux-системах.
Раньше он был только на Linux, теперь появились версии и для Windows и для MacOS!
curl -LsSf https://astral.sh/uv/install.sh | sh pip install open-webui open-webui serve pip install --upgrade open-webui
Файл «/home/mikl/programs/ollama-apps/bashrc».
export WORKON_HOME=$HOME/programs/ollama-apps/open-webui/open-webui-env export PROJECT_HOME=$HOME/programs/ollama-apps/open-webui/ export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python export VIRTUALENVWRAPPER_VIRTUALENV=/usr/bin/virtualenv # export VIRTUALENVWRAPPER_VIRTUALENV_ARGS='--no-site-packages' export PIP_VIRTUALENV_BASE=$WORKON_HOME export PIP_RESPECT_VIRTUALENV=true source /usr/local/sbin/virtualenvwrapper.sh #if [[ -r `which virtualenvwrapper.sh` ]]; then source `which virtualenvwrapper.sh`; fi
Файл «/home/mikl/programs/ollama-apps/open-webui-run.sh».
#!/bin/bash source /home/mikl/programs/ollama-apps/open-webui/bashrc workon ollama-env open-webui serve
Иконка для скачивания - «open-webui-icon.png».
И конечно же сам файл запуска на рабочем столе «Open-WebUI.desktop».
[Desktop Entry] Exec=/home/mikl/programs/ollama-apps/open-webui/open-webui-run.sh Type=Application Name=Open-WebUI Terminal=true Icon=/home/mikl/programs/ollama-apps/open-webui/open-webui-icon.png
- open-webui.git
- open-webui/desktop
- macOS (Apple Silicon) - open-webui-arm64.dmg
- macOS (Intel) - open-webui-x64.dmg
- Windows x64 - open-webui-x64-setup.exe
- Windows ARM64 - open-webui-arm64-setup.exe
- Linux x64 (AppImage) - open-webui_x64.AppImage
- Linux x64 (Debian/Ubuntu) - open-webui_amd64.deb
- Linux x64 (Snap) - open-webui_amd64.snap
- Linux x64 (Flatpak) - open-webui.flatpak
- Linux ARM64 (AppImage) - open-webui_arm64.AppImage
- Linux ARM64 (Debian/Ubuntu) - open-webui_arm64.deb
Приложение AnythingLLM
AnythingLLM — универсальный фронтенд для запуска и взаимодействия с различными локальными языковыми моделями.
- AnythingLLM Desktop MacOS Silicon
- AnythingLLM Desktop MacOS
- AnythingLLM Desktop Windows
- AnythingLLM Desktop Windows ARM64
- Docs AnythingLLM
- Mintplex-Labs AnythingLLM
- Mintplex-Labs AnythingLLM GIT
Для AnythingLLM я использую вот такую иконку «anythingllm-desktop.png» и ярлычок запуска «anythingllm-desktop.desktop» на рабочем столе.
[Desktop Entry] Name=AnythingLLM Exec=/home/mikl/programs/anythingllm-desktop/AppRun --no-sandbox %U Terminal=false Type=Application Icon=/home/mikl/programs/anythingllm-desktop/usr/share/icons/hicolor/1024x1024/apps/anythingllm-desktop.png StartupWMClass=AnythingLLM X-AppImage-Version=1.7.2 Comment=AnythingLLM Desktop Application MimeType=x-scheme-handler/anythingllm; Categories=Utility;
Приложение LM Studio
LM Studio — приложение для локального запуска и управления большими языковыми моделями с удобным графическим интерфейсом.
Иконка запуска LM Studio «lm-studio.png» и ярлычок запуска на рабочем столе «lm-studio.desktop».
[Desktop Entry] Name=LM Studio Exec=/home/mikl/programs/LM-Studio-0.3.6-8-x64/LM-Studio-0.3.6-8-x64-appimage-extract/AppRun --no-sandbox %U Terminal=false Type=Application Icon=/home/mikl/programs/LM-Studio-0.3.6-8-x64/LM-Studio-0.3.6-8-x64-appimage-extract/usr/share/icons/hicolor/0x0/apps/lm-studio.png StartupWMClass=LM Studio X-AppImage-Version=0.3.6 Comment=Use the chat UI or local server to experiment and develop with local LLMs. Keywords=developer;llm; category=Development;Utility; MimeType=x-scheme-handler/lmstudio; Categories=Development;
Appimage extract — код для распаковки и извлечения содержимого из любого AppImage-файлов на Linux.
Appimage extract:
./Application_xxx-version.AppImage --appimage-extract # Извлекли, посмотрели категорию ПО cat /usr/share/applications/Your-Apps_x-vers.desktop | grep -Ei "Categories" # Отредактировали ярлычок запуска который будем вытаскивать на рабочий стол, прописывая полные пути nano ./squashfs-root/Application_xxx-version.desktop # Ну и не забыли добавить разрешение на выполнения/запуск chmod +x ./squashfs-root/AppRun chmod +x ./squashfs-root/*.desktop # А вот так упаковываем обратно. Сначала нужна утилита для упаковки. wget "https://github.com/AppImage/AppImageKit/releases/download/continuous/appimagetool-x86_64.AppImage" chmod +x ./appimagetool-x86_64.AppImage # Упаковываем из директории squashfs-root. Все пути внутри в скриптах должны быть относительными. ARCH=x86_64 /appimagetool-x86_64.AppImage -n squashfs-root
Несколько возможных причин, по которым LM Studio не загружает модель, и способы их устранения:
- Размер модели больше объёма VRAM. Если в LM Studio пытаются выгрузить модель на графический процессор, её размер должен быть меньше объёма VRAM, чтобы модель поместилась туда. Попробуйте установить значение «GPU offload» в 0 или отключить эту функцию.
- Включение функции «Keep entire model in RAM». Если её отключить, то можно запросить модель и получить ответ.
- Использование видеокарты для загрузки модели. Если на видеокарте достаточно памяти для модели, то можно попробовать использовать её. Для этого нужно кликнуть на галочку «GPU Offloading» и убедиться, что там стоит n_layers = -1
Приложение Text-Generation-Webui
Проект потихоньку умирает и уже не везде может запускаться!
Text-Generation-Webui — веб-интерфейс для генерации текста с использованием локальных языковых моделей, поддерживает множество моделей и кастомизацию.
Linux запуск.
start_linux.sh --api --cpu start_linux.sh --api --cuda start_linux.sh --api
Иконка для text-generation-webui «text-generation-webui-logo.svg» и ярлычок запуска на рабочем столе «text-generation-webui.desktop».
[Desktop Entry] Name=Text Generation WebUI Exec=bash -c "/media/mikl/LocalDisk/Neural-Networks/text-generation-webui/start_linux.sh --api --cpu" Terminal=true Type=Application Icon=/home/mikl/programs/ollama-apps/text-generation-webui-logo.svg StartupWMClass=TextGenerationWebUI X-AppImage-Version=1.7.2 Comment=Text-Generation-WebUI Desktop Application MimeType=x-scheme-handler/textgenerationwebui; Categories=Utility;
Приложение Miniconda3
Miniconda3 — минималистичный дистрибутив Python с менеджером пакетов conda для управления окружениями и зависимостями.
Запуск на Linux.
wget https://repo.anaconda.com/miniconda/Miniconda3-py38_23.5.2-0-Linux-x86_64.sh sudo bash ./Miniconda3-py38_23.5.2-0-Linux-x86_64.sh conda update -n base -c defaults conda
Приложение TavernAI для Text-Generation-Webui
TavernAI для Text-Generation-Webui — расширение для Text-Generation-Webui, добавляющее удобный интерфейс для ролевых игр и чат-ботов.
Приложение Stable-Diffusion-Webui
Stable-Diffusion-Webui — популярный веб-интерфейс для локального запуска модели Stable Diffusion с множеством расширений и поддержкой LoRA.
- Stable-Diffusion-Webui Git https
- Stable-Diffusion-Webui Git git
Откуда берется первоначальная модель для Stable Diffusion WebUI от AUTOMATIC1111?
При первом запуске Stable Diffusion WebUI сама программа не содержит встроенной модели — её нужно скачать отдельно. Обычно для работы требуется файл модели (например, с расширением «.ckpt» или «.safetensors»), который содержит веса нейросети.
- Часто рекомендуют скачивать модели с таких ресурсов, как Civitai или Huggingface. Например, в документации и обсуждениях упоминается, что можно скачать модель с Civitai напрямую и положить в папку models/Stable-diffusion внутри папки с WebUI.
- Если Civitai недоступен или не работает, можно использовать альтернативные источники, например, Huggingface.
Как перенести модели и нейросети с одного ПК на другой?
Если у вас уже была установлена программа на одном из ПК и там есть скачанные модели, то:
- Найдите папку с моделями на старом ПК. Обычно это: stable-diffusion-webui/models/Stable-diffusion/
- Скопируйте оттуда все файлы моделей (.ckpt, .safetensors и т.п.).
- Перенесите эти файлы в такую же папку на новом ПК, где установлена WebUI.
- Запустите WebUI — она должна обнаружить модели и использовать их без необходимости скачивать заново.
Ссылки на .ckpt и .safetensors stable-diffusion модели.
- stable-diffusion-v1-5 / stable-diffusion-v1-5
- czl/stable-diffusion-v1-5
- Comfy-Org / stable-diffusion-3.5
- Stability AI репозиторий
Приложение one-click-installers
one-click-installers — скрипты и установщики для быстрого развёртывания Text-Generation-Webui и связанных инструментов.
Приложение KoboldAI или KoboldAI GIT
KoboldAI или KoboldAI GIT — платформа для интерактивного сторителлинга и генерации текста с поддержкой различных языковых моделей.
- KoboldAI-Client Git https
- KoboldAI-Client Git git
- KoboldAI United (Экспериментальная версия) Git https
- KoboldAI United (Экспериментальная версия) Git git
- KoboldAI CU Git https
- KoboldAI CU Git git
- Colab KoboldAI GPU
- Colab KoboldAI TPU
Пока Google не исправит драйвера для TPU, эта версия бесполезна.
Программа Krita
Krita — бесплатный и мощный редактор растровой графики, ориентированный на цифровую живопись и иллюстрацию.
Например.
- krita-x64-5.2.9-setup.exe
- krita-x64-5.2.9.zip
- krita-5.2.9-x86_64.AppImage
- KritaShellExtension-v1.2.4b-setup.exe
Внедрение Diffusion в Krita.
Приложение Krita AI Diffusion
Krita AI Diffusion — плагин для Krita, позволяющий использовать модели диффузии для генерации и редактирования изображений.
Программа SubTitleEdit
SubTitleEdit — редактор субтитров с поддержкой автоматического создания и перевода субтитров с помощью встроенного AI.
«stabilityai/stable-diffusion-3.5-large-turbo»
stabilityai/stable-diffusion-3.5-large-turbo — улучшенная версия модели Stable Diffusion для генерации изображений с высоким качеством и скоростью.
stabilityai/stable-diffusion-3.5-large-turbo
«Image Creator»
Image Creator — инструмент для генерации изображений на основе текстовых подсказок с использованием локальных моделей.
«Stability Matrix»
Stability Matrix — платформа или инструмент для управления и анализа моделей Stable Diffusion и их параметров.
Иконка запуска StabilityMatrix «zone.lykos.stabilitymatrix.png» и ярлычок на рабочем столе «Stability_Matrix_AppImage.desktop».
[Desktop Entry] Type=Application Name=Stability Matrix Icon=/home/mikl/programs/StabilityMatrix-apps/StabilityMatrix-AppImage/zone.lykos.stabilitymatrix.png Comment=Package and checkpoint manager for Stable Diffusion. Exec=/home/mikl/programs/StabilityMatrix-apps/StabilityMatrix-AppImage/usr/bin/StabilityMatrix.Avalonia TryExec=/home/mikl/programs/StabilityMatrix-apps/StabilityMatrix-AppImage/usr/bin/StabilityMatrix.Avalonia NoDisplay=false X-AppImage-Integrate=true Terminal=false Categories=Utility; MimeType= Keywords=
В самой программе на достаточно древнем оборудовании - 2 ядра, 2 потока, без видеокарты, с 16 ГБ опертивной памяти - мне удалось протестировать несколько моделей. И даже с такими низкими параметрами удалось использовать модели с низкой квантизацией. И даже в этом случае не смотря на то, что генерация занимала чуть ли не целый час - результат был на уровне серьезных платных онлайн ресурсов.
Для тестов были использованы модели с CivitAI встроенного браузера.
- DreamShaper
- epiCRealism
- Erotic Vision
- PornRealistic
- PornVision
- v1-5-Pruned-emaonly
Что делать, если Civitai не работает?
- Можно скачать модель с другого источника вручную и положить её в папку с моделями.
- Важно, чтобы файл модели имел правильное имя, например, model.ckpt или model.safetensors, и находился в папке stable-diffusion-webui/models/Stable-diffusion/.
- После этого при запуске WebUI программа подхватит модель и загрузит её для работы.
«DALL·E mini»
DALL·E mini (теперь известна как Craiyon) — это упрощённая версия модели DALL·E для генерации изображений по текстовому описанию.
Работает на Windows, Linux, macOS, но для комфортной работы нужен GPU с минимум 6-8 ГБ видеопамяти.
Она доступна как веб-сервис и как локальная программа (на Python), но локальный запуск требует мощного железа и настройки.
«SillyTavern»
SillyTavern - пользовательский интерфейс для взаимодействия с языковыми моделями ИИ (LLM), ориентированный на ролевые игры и кастомизированное общение.
SillyTavern — дружелюбный интерфейс для roleplay, KoboldCpp — высокопроизводительный бэкенд, запускающий модели локально. Вместе они дают полностью приватные, нелимитированные взаимодействия без интернета.
Ollama — ещё проще: ollama run mistral и всё готово, потом подключаешь SillyTavern к localhost:11434.
SillyTavern сам по себе — локально устанавливаемый интерфейс, форк TavernAI 1.2.8 с февраля 2023, уже более 300 контрибьюторов, бесплатный и open-source. Требования к железу минимальны — работает на всём, что запускает NodeJS 20+. Поддерживает character cards, lorebooks, память, групповые чаты.
«KoboldCpp»
KoboldCpp — это лёгкое open‑source‑приложение для локального запуска больших языковых моделей (LLM) в форматах GGML и GGUF. Основано на движке llama.cpp, включает встроенный веб‑интерфейс и API для разработчиков.
KoboldCpp — один бинарник, запускается без установки, поддерживает GGUF-модели, работает на CPU+GPU. Простой в использовании API с CPU-offloading (полезно при малом VRAM) и стримингом — запускается из одного файла на Windows, Mac и Linux.
«Axolotl»
Axolotl — это open‑source‑инструмент с лицензией Apache 2.0 для тонкой настройки (fine‑tuning) больших языковых моделей (LLM), в т. ч. с поддержкой LoRA, QLoRA и полного fine‑tuning. Разработан коллективом OpenAccess‑AI‑Collective.
«Backyard AI»

«InvokeAI»
https://github.com/invoke-ai/InvokeAI
1.2. Параметры
1.2.1. VRAM и RAM для запуска модели
Определить, сколько слоёв поставить для модели GGUF исходя из имеющейся видеокарты, можно с помощью параметра num_gpu. В последних версиях Ollama его можно указать в интерактивном режиме, и программа загрузит оптимальное количество слоёв с учётом доступной видеопамяти.
Можно ли совместно использовать VRAM и RAM для запуска модели?
Да, в принципе можно. Это называется offloading — когда часть модели или вычислений размещается в видеопамяти GPU, а остальное — в оперативной памяти CPU. Такой подход позволяет запускать модели, которые не помещаются полностью в VRAM, но при этом использовать ускорение GPU для тяжелых вычислений.
Также есть рекомендации по выбору моделей GGUF в зависимости от объёма видеопамяти видеокарты:
- 4–6 ГБ VRAM — модели Q3_K_M или Q4_K_S;
- 8 ГБ VRAM — модели Q4_K_M или Q5_K_S;
- 12–16 ГБ VRAM — модели Q5_K_M или Q6_K;
- 24 ГБ VRAM — модели Q6_K или Q8_0.
Выбор количества слоёв и модели зависит от конкретных условий и требований пользователя.
В принципе эти же значения VRAM можно использовать для определения какие модели лучше подойдут к вашей конкретной оперативной памяти.
text-generation-webui (с backend llama.cpp или ggml)
Поддерживает offload — часть весов модели можно хранить в RAM, а часть — в VRAM.
Для этого есть параметры запуска, например:
--offload-vectors-to-cpu
--load-in-8bit
--gpu-layers N
где N — количество слоёв, которые будут загружены на GPU, а остальные — в RAM.
Это позволяет эффективно использовать 12 ГБ VRAM для ускорения, а 64 ГБ RAM — для хранения остальной части модели.
Open WebUI
Аналогично text-generation-webui, поддерживает offloading через параметры запуска и настройки.
Можно указать, сколько слоёв модели грузить на GPU, а сколько — в RAM.
AnythingLLM, TavernAI, msty app
Поддержка offload зависит от движка, на котором они основаны. Если они используют llama.cpp или huggingface transformers с offload, то можно настроить аналогично.
Ollama
Обычно ориентирован на GPU, но может иметь свои настройки offload. Нужно смотреть документацию.
Как настроить offload в text-generation-webui (пример)
Запустите сервер с параметрами, например:
python server.py --model models/medicus --gpu-layers 20 --offload-vectors-to-cpu
И тогда.
--gpu-layers 20 — загрузить первые 20 слоёв модели на GPU (ускорение).
Остальные слои будут в RAM.
--offload-vectors-to-cpu — переносит векторы (часть весов) в оперативную память.
Можно экспериментировать с числом слоёв, чтобы найти баланс между VRAM и RAM.
Важные моменты
- Offload снижает требования к VRAM, но увеличивает задержки из-за передачи данных между CPU и GPU.
- 64 ГБ RAM — отличный запас для offload, позволит запускать большие модели, которые не помещаются в 12 ГБ VRAM.
- Обязательно используйте последние версии ПО и драйверов NVIDIA для лучшей поддержки CUDA и offload.
Рекомендации по числу слоёв для offload на RTX 5070 с 12 ГБ VRAM
- Стартуйте с 10–20 слоёв на GPU
- Если модель большая или VRAM начинает заканчиваться, уменьшайте число слоёв на GPU
- Если VRAM хватает, можно увеличить число слоёв до 30 и более
Это наиболее распространённый диапазон для карт с 12 ГБ VRAM и моделей среднего размера (7B–13B параметров). Такой объём слоёв обычно помещается в VRAM и даёт заметное ускорение.
Например, попробуйте 8, 6 или даже 4 слоя, чтобы освободить VRAM, но при этом сохранить ускорение.
Это даст максимальное ускорение, но требует больше памяти на GPU.
1.2.2. Квантизации и требования к оперативной памяти
Квантизация Описание и особенности Примерный объём RAM для запуска Рекомендации для вашего ПК (16 ГБ RAM).
- Q8 (8 бит) ~12-16 ГБ и выше
- Q6_K ~10-12 ГБ
- Q5_K_M ~8-10 ГБ
- Q4_K_M ~6-8 ГБ
- Q3_K_S ~4-6 ГБ
- Q2_K ~3-5 ГБ
Высокая точность, большая модель по размеру и памяти.
Средняя точность, уменьшенный размер модели.
Средняя-низкая точность, уменьшенный размер.
Низкая точность, сильно уменьшенный размер.
Оптимальный вариант для 16 ГБ RAM — баланс качества и производительности.
Очень низкая точность, минимальный размер.
Хорошо подходит для слабых систем, качество генерации падает, но запуск стабильный.
Минимальная точность, самый маленький размер.
Максимально лёгкая квантизация, подходит для очень слабых систем, качество генерации заметно хуже.
Пояснения.
- Объём RAM — это ориентировочные значения, включающие загрузку модели и работу самого text-generation-webui.
- Чем ниже битность квантизации, тем меньше памяти требуется, но качество генерации может ухудшаться.
- Ваши 16 ГБ оперативной памяти позволяют комфортно запускать модели с квантизацией Q4_K_M и ниже.
- Квантизации Q5_K_M и выше могут работать, но с риском нехватки памяти и сильной нагрузки на CPU.
- Для слабого CPU и отсутствия GPU рекомендуется выбирать более низкие квантизации (Q4_K_M, Q3_K_S, Q2_K) для приемлемой скорости.
Рекомендации по запуску на вашем ПК.
- Оптимальный выбор: Q4_K_M — хорошее качество при приемлемых требованиях к памяти.
- Если хочется снизить нагрузку: Q3_K_S или Q2_K — минимальные требования, но качество генерации падает.
- Не рекомендуется: Q8 и Q6_K — слишком тяжёлые для 16 ГБ RAM и слабого CPU.
Вот краткая сводка по квантизациям, на Ryzen 7 7800X3D, 64 ГБ RAM и RTX 5070 (12 ГБ VRAM):
- Запуск только на CPU (Ryzen 7 7800X3D, 64 ГБ RAM)
- Запуск только на GPU (RTX 5070, 12 ГБ VRAM)
- Запуск совместно CPU + GPU (offload)
Рекомендуемые квантизации: Q4_K_M, Q3_K_S, Q2_K
Почему: Ryzen 7 7800X3D — мощный 8-ядерный процессор с 16 потоками и большим кэшем, отлично подходит для CPU-инференса, но без GPU нагрузка будет высокой. 64 ГБ RAM позволяет комфортно запускать модели с квантизацией Q4_K_M и ниже.
Ожидаемая производительность: Медленнее, чем с GPU, но стабильная работа с умеренным качеством.
Рекомендуемые квантизации: Q4_K_M, Q5_K_S, возможно Q5_K_M (с оптимизациями)
Почему: 12 ГБ VRAM позволяет запускать модели с квантизацией до Q5_K_M, но лучше ориентироваться на Q4_K_M или Q5_K_S для стабильности и скорости.
Ожидаемая производительность: Быстрая генерация, хорошее качество, но ограничение по размеру модели из-за VRAM.
Рекомендуемые квантизации: Q5_K_M, Q6_K, возможно Q6_K с offload
Почему: Offload позволяет хранить часть модели в RAM (64 ГБ) и часть — в VRAM (12 ГБ), что расширяет возможности запуска более крупных и точных моделей. Ryzen 7 7800X3D обеспечит хорошую поддержку CPU-части, а RTX 5070 ускорит вычисления.
Ожидаемая производительность: Оптимальный баланс между качеством и скоростью, с возможностью запускать более тяжёлые модели, чем на одном GPU или CPU.
1.2.3. Форматы с плавающими точками
Стандартные форматы:
- FP64 - 64 бита - Научные вычисления с высокой точностью
- FP32 - 32 бита - Стандартный формат для нейросетей
- FP16 - 16 бит - Экономия памяти в 2 раза
- BF16 - 16 бит - Похож на FP32 по структуре, но экономнее
Квантизированные форматы:
- INT8 - 8 бит - В 4 раза меньше FP32
- INT4 - 4 бита - В 8 раз меньше FP32
- 1.58-бит - ~1.58 бита - До 20 раз меньше FP32
FP64, или 64-битные числа с плавающей запятой, применяются там, где малейшая ошибка может привести к неверным результатам. В таких областях, как космическая индустрия, моделирование траекторий спутников или расчёты по гидродинамике, отклонение даже на малую величину может иметь самые серьёзные последствия.
FP32: баланс между точностью и скоростью
FP32 — это стандартный 32-битный формат, который используется в большинстве повседневных задач, таких как рендеринг графики, обработка изображений и обучение нейросетей. Он обеспечивает достаточную точность при высокой производительности, что делает его оптимальным выбором для задач, где скорость важнее точности.
FP16: ускорение обработки данных
FP16 — это 16-битный формат, который позволяет значительно ускорить вычисления за счёт уменьшения точности, но без существенного ущерба для качества результата. Этот формат активно используется в задачах машинного обучения и нейросетей, где важна высокая скорость обработки больших объёмов данных.
BFLOAT16 — это формат, который чаще всего используется для инференса, то есть для выполнения уже обученных моделей. Он позволяет существенно ускорить обработку данных без значительных потерь в точности, что особенно полезно в задачах, связанных с анализом данных в реальном времени.
FP8 — это новый формат, который используется для выполнения операций с максимальной скоростью при минимальных затратах ресурсов. Этот формат хорошо подходит для инференса, где точность не так важна, как скорость, например, в задачах, связанных с компьютерным зрением или распознаванием объектов в реальном времени.
Каждый тип float — будь то FP64, FP32, FP16, BFLOAT16 или FP8 — имеет своё применение и должен выбираться в зависимости от задачи. FP64 — для научных расчётов, FP32 — для баланса между производительностью и точностью, FP16 — для обучения нейросетей, а BFLOAT16 и FP8 — для инференса. Современные ускорители Nvidia Tesla, Radeon Instinct или Intel GPU Max поддерживают все эти форматы, что позволяет вам максимально эффективно использовать мощь GPU для каждой конкретной задачи.
Например.
python llama.cpp/convert.py vicuna-hf \ --outfile vicuna-13b-v1.5.gguf \ --outtype q8_0
1.2.4. Архитектура Transformer
Transformer — основа современных LLM. Практически все современные модели:
- Llama
- Qwen
- Mistral
- Gemma
- DeepSeek
- Mixtral
- Phi
- Yi
- Command-R и другие...
Главная идея: модель смотрит на весь контекст одновременно через механизм attention.
Почему Transformer победил:
- GPU отлично параллелят attention
- Transformer масштабируется
- модель может учитывать дальние зависимости
- обучение быстрее RNN/LSTM
Главные компоненты:
- Self-Attention
- Multi-Head Attention
- Feed Forward Layers
- Positional Embeddings
- Residual Connections
- LayerNorm
Self-Attention: каждый токен вычисляет важность других токенов.
Например: «Кот сидел на стуле. Он был мягкий.»
Модель должна понять: «он» относится к «стулу».
Attention вычисляет вероятности связей.
RoPE: Rotary Positional Embedding. Используется почти во всех современных LLM.
Зачем нужен:
- Transformer сам по себе не понимает порядок слов.
- RoPE кодирует позицию токенов.
Почему контекст ограничен:
- Attention complexity растёт квадратично.
- Чем больше токенов — тем больше VRAM.
Практика:
- 8k context — легко.
- 32k — уже тяжело.
- 128k — огромные требования к памяти.
Полезные ссылки:
1.2.5. Tokenization и токены
LLM не видят текст как человек. Они работают с токенами.
Токен: фрагмент текста.
Русский язык: обычно требует больше токенов чем английский.
Почему: английские токенизаторы обучались преимущественно на английском.
Основные токенизаторы:
- BPE
- SentencePiece
- WordPiece
Специальные токены:
- BOS — начало текста.
- EOS — конец текста.
ChatML: формат диалогов:
<|system|> <|user|> <|assistant|>
Почему длинные RP сообщения опасны:
- каждый токен хранится в KV-cache.
- Чем длиннее диалог — тем выше VRAM.
Полезно:
1.2.6. KV Cache и VRAM
KV-cache — одна из важнейших тем локального inference.
Когда модель читает контекст: она вычисляет attention значения.
Чтобы не пересчитывать всё заново: значения сохраняются в KV-cache.
Что хранится:
- Keys
- Values
Почему контекст жрёт VRAM: KV-cache хранится в памяти GPU.
Пример:
- 7B модель:
- 8k context — нормально
- 32k — VRAM резко растёт
- 128k — огромная нагрузка
Prompt Processing: обработка входного текста.
Token Generation: генерация нового токена.
Prompt processing: обычно медленнее.
Generation: обычно быстрее.
Paged Attention:
- используется в vLLM.
- Позволяет эффективнее управлять KV-cache.
например, --kv-cache-type q8_0 в llama.cpp позволяет увеличить контекст без взрывного роста VRAM.
Полезные ссылки:
1.2.7. GGUF, EXL2, GPTQ и AWQ
GGUF: главный формат llama.cpp.
Плюсы:
- CPU support
- Vulkan
- Metal
- CUDA
- универсальность
Минусы:
- не самый быстрый на NVIDIA
EXL2: лучший формат для NVIDIA.
Используется:
- roleplay
- большие модели
- быстрый inference
Почему EXL2 быстрее: ExllamaV2 использует оптимизированные CUDA kernels.
GGUF: лучше для portability.
EXL2: лучше для скорости.
GPTQ: старый CUDA quantization format.
AWQ: более современный quantization.
Поиск моделей:
- GGUF Q4_K_M
- EXL2 4.5bpw
Популярные размеры:
- Q4_K_M
- Q5_K_M
- EXL2 4bpw
- EXL2 5bpw
Практика: CPU only: GGUF.
NVIDIA: EXL2.
Mac: MLX.
Ссылки:
EXL2 — это современный и очень быстрый формат квантизации для GPU от NVIDIA. Главное, что нужно о нём знать — это переменная битность (mixed-precision). Вместо того чтобы использовать одинаковое количество бит на все веса, EXL2 выделяет больше битов важным слоям и меньше — менее важным. Это позволяет добиться лучшего качества при меньшем расходе VRAM.
Как работает квантизация EXL2 (для понимания)?
- Базовая идея: Квантизация снижает точность числовых весов модели (например, с 16 бит до 4), что радикально сокращает потребление памяти (70B модель в 4-bit занимает ~35 ГБ вместо 140 ГБ).
- Ключевое преимущество EXL2: Это смешанная квантизация. Он сам определяет, каким слоям важна высокая точность, а какие можно сжать сильнее. Это делает EXL2 более гибким и эффективным, чем статические форматы вроде GPTQ.
- Производительность: Обеспечивает очень высокую скорость инференса, сравнимую с нативными FP16 моделями, при значительной экономии VRAM. Некоторые источники утверждают, что для 7B моделей можно достигать 56-64 токенов в секунду.
- Где искать: EXL2 модели на Hugging Face часто имеют в названии "exl2" или "ExLlamav2".
- Пользователи, такие как LoneStriker, TheBloke, bartowski, royallab, регулярно выкладывают кванти.
- Важно: В репозитории может быть несколько веток (branches), где main часто содержит только файл измерений (measurement.json), а сами кванти лежат в ветках типа 4bpw, 5bpw и т.д..
Запуск EXL2 моделей: руководство по ПО.
EXL2 — не универсальный формат. Для его запуска нужно использовать специальные бэкенды.
- Axolotl: ❌ Напрямую не поддерживает обучение моделей в формате EXL2.
- KoboldAI: ❌ Напрямую не поддерживает. Вы можете использовать TabbyAPI (см. ниже) и подключить его как API.
- KoboldCPP: ❌ Напрямую не поддерживает. KoboldCPP заточен под модели GGUF и GGML.
- SillyTavern: ✅ Поддерживает через TabbyAPI или Oobabooga. Подключите бэкенд через API. Предпочтительный способ — TabbyAPI (инструкция ниже).
- Open WebUI: ✅ Поддерживает через любой OpenAI-совместимый API. Если запустить модель через TabbyAPI или Text Generation WebUI, Open WebUI сможет с ней работать.
- Ollama: ✅ Может работать, но с оговоркой. Ollama не имеет нативной поддержки EXL2, но к модели можно подключиться через API, если она запущена, например, через TabbyAPI.
🚀 Основной способ: TabbyAPI + SillyTavern / Open WebUI
- Установите TabbyAPI (серверная часть):
- Настройте config.yml: Укажите путь к вашей EXL2 модели в параметре model_name.
- Запустите сервер TabbyAPI из командной строки. Вы должны увидеть, что модель загружена, и доступен API-ключ.
- Настройте SillyTavern или Open WebUI:
- В SillyTavern:
- В настройках API выберите Text Completion и затем TabbyAPI.
- Введите API URL (по умолчанию http://127.0.0.1:5000) и API Key из терминала TabbyAPI.
- Новичкам: Официальное дополнение TabbyAPI Loader можно установить из вкладки "Extensions" SillyTavern для удобной загрузки моделей прямо из интерфейса.
- В Open WebUI: Подключите TabbyAPI как любой другой OpenAI-совместимый API (OpenAI, TextGenWebUI) — аналогично SillyTavern.
git clone https://github.com/theroyallab/tabbyAPI.git cd tabbyAPI pip install -r requirements.txt
Конвертация GGUF → EXL2: это не прямой процесс.
Из-за различий в архитектуре форматов и алгоритмах квантизации, прямая конвертация «на лету» из GGUF в EXL2 невозможна. Процесс всегда требует возврата к исходным FP16 весам.
Правильный алгоритм действий:
- Найдите FP16 версию вашей модели. Ищите на Hugging Face оригинальный репозиторий модели (часто помечен как original, fp16 или base).
- Конвертируйте FP16 → EXL2, используя инструменты:
- Официальный скрипт от разработчика ExLlamaV2 на GitHub.
- Инструменты-помощники:
- FusionQuant (Docker): имеет удобный двухэтапный пайплайн (merge + конвертация) и поддерживает EXL2.quantkit (CLI): мощный инструмент с единой командой для конвертации в несколько форматов, включая EXL2.
- quantkit (CLI): мощный инструмент с единой командой для конвертации в несколько форматов, включая EXL2.
Работа с LoRA для EXL2 моделей.
Это самый нетривиальный момент. Стандартные LoRA-адаптеры, созданные под модель в FP16, несовместимы с квантованной версией напрямую.
- Прямой способ: Загружать и модель, и LoRA через ExLlamaV2, а не через AutoGPTQ или bitsandbytes. ExLlamaV2 умеет "применять" адаптер к квантованной модели на лету.
- Создание EXL2-модели с "зашитой" LoRA: Самый надёжный способ — слить LoRA-адаптер с FP16 базовой моделью (объединить их в единые веса) и затем сквантовать полученную FP16-модель в EXL2. Для слияния удобно использовать mergekit (например, в связке с FusionQuant).
1.2.8. llama.cpp и KoboldCpp
llama.cpp — главный локальный inference engine.
GitHub: llama.cpp
Поддерживает:
- CPU
- CUDA
- Vulkan
- ROCm
- Metal
Linux установка:
git clone https://github.com/ggerganov/llama.cpp cd llama.cpp cmake -B build cmake --build build -j
CUDA:
cmake -B build -DGGML_CUDA=ON
Запуск:
./build/bin/llama-cli -m model.gguf
KoboldCpp: GUI поверх llama.cpp.
Плюсы:
- простой запуск
- RP support
- встроенный сервер
- Windows friendly
Минусы:
- production хуже vLLM
1.2.9. vLLM и production inference
vLLM — production inference engine.
Почему важен: это уже enterprise-grade inference.
Особенности:
- batching
- Paged Attention
- OpenAI-compatible API
- высокая throughput производительность
Установка:
pip install vllm
Запуск:
python -m vllm.entrypoints.openai.api_server --model MODEL_PATH
API:
http://localhost:8000/v1
Почему vLLM быстрее: он умеет объединять запросы пользователей.
Ollama: ориентирован на простоту.
vLLM: ориентирован на production.
Используется:
- AI сервисами
- web apps
- массовым inference
GPU: рекомендуется NVIDIA.
Полезно: https://docs.vllm.ai/
1.2.10. TabbyAPI и EXL2 RP stack
TabbyAPI — один из лучших backends для RP.
Работает через: ExllamaV2.
Плюсы:
- высокая скорость
- EXL2 support
- OpenAI API
- SillyTavern compatibility
Установка:
git clone https://github.com/theroyallab/tabbyAPI cd tabbyAPI python -m venv env Linux: source env/bin/activate Windows: env\Scripts\activate pip install -r requirements.txt python main.py
Почему RP community любит TabbyAPI: EXL2 даёт очень высокую скорость на NVIDIA.
Особенно: RTX 3060/4060/4090.
Рекомендуется: 4.5bpw EXL2.
1.2.11. SillyTavern и RP ecosystem
SillyTavern — главный frontend для RP.
NodeJS: https://nodejs.org/
Установка:
git clone https://github.com/SillyTavern/SillyTavern cd SillyTavern npm install npm start
Подключение:
- TabbyAPI
- KoboldCpp
- Ollama
- OpenAI API
Главные системы:
- Character Cards: PNG или JSON.
- personality
- scenario
- greeting
- examples
- Lorebooks: автоматическая подгрузка знаний.
- Author Note: скрытая инструкция модели.
- Memory
- Vector Memory
- Regex
- Extensions
Sampling: Temperature: управляет randomness.
Top-P: вероятностная выборка.
Min-P: стабильность.
DRY: уменьшает повторения.
Почему sampler критичен: иногда sampler влияет сильнее самой модели.
Character cards: https://chub.ai/
RP модели:
- MythoMax
- Noromaid
- Midnight Miqu
- EVA-Qwen
1.2.12. RAG и векторные базы
RAG: Retrieval-Augmented Generation.
Позволяет модели:
- читать документы
- искать знания
- использовать память
Главная идея: не хранить всё в контексте.
Pipeline:
- Разбить документы
- Создать embeddings
- Сохранить vectors
- Выполнять semantic search
- Передавать найденный текст LLM
Главные библиотеки:
- Chroma: https://www.trychroma.com/
- Qdrant: https://qdrant.tech/
- FAISS: https://github.com/facebookresearch/faiss
- LangChain: https://www.langchain.com/
- LlamaIndex: https://www.llamaindex.ai/
Установка:
pip install chromadb qdrant-client sentence-transformers
Embeddings: это vector representation текста.
Популярные embedding модели:
- BGE
- E5
- nomic-embed
Chunking: разделение документов.
Практика: слишком большие chunks ухудшают retrieval.
1.2.13. LoRA, QLoRA и Fine-Tuning
Datasets: https://huggingface.co/datasets
Популярные:
- OpenHermes
- UltraChat
- PIPPA
- ShareGPT
Главные параметры LoRA:
- rank: размер адаптера.
- alpha: сила обучения.
- dropout: устойчивость.
- target_modules: какие слои обучать.
- Проблемы: catastrophic forgetting.
- Практика: плохой dataset убивает модель.
- Flash Attention: уменьшает VRAM.
- DeepSpeed: ускоряет обучение.
1.2.14. CUDA, ROCm и ускорение
CUDA: главная AI платформа NVIDIA.
Скачать: https://developer.nvidia.com/cuda-downloads
PyTorch: https://pytorch.org/
Проверка CUDA:
python -c "import torch; print(torch.cuda.is_available())"
- ROCm: AMD аналог CUDA.
- Flash Attention: https://github.com/Dao-AILab/flash-attention
- xFormers: https://github.com/facebookresearch/xformers
- bitsandbytes: https://github.com/TimDettmers/bitsandbytes
Почему NVIDIA доминирует: CUDA ecosystem значительно зрелее.
AMD: улучшается, но проблем больше.
Intel: пока слабее.
Практика: для AI чаще всего рекомендуют NVIDIA.
1.2.15. MLA (Multi-head Latent Attention)
Это новая архитектура внимания, предложенная DeepSeek в их модели V2. Если совсем просто — это способ заставить LLM (Large Language Model — большая языковая модель) "думать" намного быстрее и использовать меньше видеопамяти (VRAM), особенно при работе с длинными текстами.
💡 Аналогия: Библиотекарь и Конспекты
Представь, что традиционное "внимание" модели (Multi-Head Attention, MHA) — это библиотекарь, который для ответа на каждый вопрос заново ходит к огромному стеллажу, берет с него все книги целиком (ключа и значение — K и V) и пытается найти в них ответ. Это занимает много места (нужно держать все книги рядом) и времени.
А MLA — это очень умный библиотекарь. Он не таскает все книги, а предварительно делает краткие конспекты (сжимает в latent space — скрытое/потенциальное пространство). Когда ему задают вопрос, он берет не огромные книги, а только этот маленький конспект. Это занимает в разы меньше места и позволяет ориентироваться намного быстрее.
1.2.16. Flash Attention 3
Это третья версия алгоритма для супер-быстрого расчета одного из самых "тяжелых" компонентов в архитектуре трансформера — механизма внимания. Простыми словами, это ультра-оптимизированный инструмент, который заставляет видеокарту работать на пределе ее возможностей.
💡 Аналогия: Конвейер на Заводе
Старый способ расчета внимания был неэффективен: конвейер завода то включался, то выключался, тратя время на загрузку деталей. FlashAttention переделал конвейер так, чтобы основная работа велась без остановок (использование быстрой памяти GPU — SRAM вместо HBM). FlashAttention-3 — это как добавить роботизированные руки и систему предзаказа. Теперь параллельно можно выполнять несколько операций, а детали доставляются еще до того, как они понадобятся (асинхронность). Это позволило «выжать» из современных видеокарт почти все их теоретические ресурсы.
1.3. Модели
Важный нюанс. Ниже указан список только примеров моделей, которые удалось найти мне, и которые мне больше всего понравились.
Рекомендую искать модели на официальных сайтах.
Либо просто забивайте в поиск и ищите по различным GIT репозиториям. В иделае неплохо, если найдете модель формата GGML/GGUF, которую можно конвертировать в ollama, либо использовать напрямую в Text-Generation-Webui и других похожих ПО.
Таким же образом можно найти различные LORa дополнения как для текстовых моделей, так и для генерации и обработки изображений и другие.
«Mykes/medicus»
Medicus — это медицинская адаптация модели Gemma2-2b-it, специально дообученная для применения в сфере здравоохранения и медицины. Модель поддерживает русский и английский языки, что делает её универсальной для использования в различных медицинских контекстах. Дообучение модели проводилось методом Continued Pretraining в течение 10 эпох, что позволило адаптировать её под задачи медицинской тематики.
- Q8 8-битная квантизация (стандарт)
- Q6_K 6-битная квантизация с использованием K-средних
- Q5_K_M 5-битная квантизация с K-средними, смешанная точность
- Q4_K_M 4-битная квантизация с K-средними, смешанная точность
- Q3_K_S 3-битная квантизация с K-средними, малая
- Q2_K 2-битная квантизация с K-средними
git lfs install git clone https://huggingface.co/Mykes/medicus # If you want to clone without large files - just their pointers GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/Mykes/medicus # CLI # Make sure hf CLI is installed: pip install -U "huggingface_hub[cli]" hf download Mykes/medicus
config.json
generation_config.json
medicus-F16.gguf
medicus-Q2_K.gguf
medicus-Q3_K_S.gguf
medicus-Q4_K_M.gguf
medicus-Q5_K_M.gguf
medicus-Q6_K.gguf
medicus-Q8_0.gguf
model-00001-of-00002.safetensors
model-00002-of-00002.safetensors
model.safetensors.index.json
special_tokens_map.json
tokenizer.json
tokenizer.model
tokenizer_config.json
«TheBloke/medalpaca-13B-GGUF»
medalpaca-13B-GGUF — это большая языковая модель, специально доработанная для задач медицинской области. Она основана на LLaMA (Large Language Model Meta AI) и содержит 13 миллиардов параметров. Основная цель этой модели — улучшение задач ответов на вопросы и медицинского диалога.
huggingface-cli download TheBloke/medalpaca-13B-GGUF medalpaca-13b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
.gitattributes
README.md
config.json
medalpaca-13b.Q2_K.gguf
medalpaca-13b.Q3_K_L.gguf
medalpaca-13b.Q3_K_M.gguf
medalpaca-13b.Q3_K_S.gguf
medalpaca-13b.Q4_0.gguf
medalpaca-13b.Q4_K_M.gguf
medalpaca-13b.Q4_K_S.gguf
medalpaca-13b.Q5_0.gguf
medalpaca-13b.Q5_K_M.gguf
medalpaca-13b.Q5_K_S.gguf
medalpaca-13b.Q6_K.gguf
medalpaca-13b.Q8_0.gguf
«TheBloke/med42-70B-GGUF»
med42-70B-GGUF — это клиническая большая языковая модель (LLM) с открытым доступом, разработанная компанией M42 для расширения доступа к медицинским знаниям. Созданная на основе LLaMA-2 и содержащая 70 миллиардов параметров, эта генеративная система искусственного интеллекта предоставляет высококачественные ответы на медицинские вопросы.
huggingface-cli download TheBloke/med42-70B-GGUF med42-70b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
.gitattributes
LICENSE.txt
Notice
README.md
USE_POLICY.md
config.json
med42-70b.Q2_K.gguf (29.3 GB)
med42-70b.Q3_K_L.gguf (36.1 GB)
med42-70b.Q3_K_M.gguf (33.2 GB)
med42-70b.Q3_K_S.gguf (29.9 GB)
med42-70b.Q4_0.gguf (38.9 GB)
med42-70b.Q4_K_M.gguf (41.4 GB)
med42-70b.Q4_K_S.gguf (39.1 GB)
med42-70b.Q5_0.gguf (47.5 GB)
med42-70b.Q5_K_M.gguf (48.8 GB)
med42-70b.Q5_K_S.gguf (47.5 GB)
med42-70b.Q6_K.gguf-split-a (28.3 GB)
med42-70b.Q6_K.gguf-split-b (28.3 GB)
med42-70b.Q8_0.gguf-split-a (36.6 GB)
med42-70b.Q8_0.gguf-split-b (36.6 GB)
«gemma3:4b»
The current, most capable model that runs on a single GPU.
Gemma is a lightweight, family of models from Google built on Gemini technology. The Gemma 3 models are multimodal—processing text and images—and feature a 128K context window with support for over 140 languages. Available in 1B, 4B, 12B, and 27B parameter sizes, they excel in tasks like question answering, summarization, and reasoning, while their compact design allows deployment on resource-limited devices.
4.3 GB
ollama run gemma3:4b
«codegemma»
codegemma — это набор мощных, но легких моделей, которые могут выполнять различные задачи кодирования, такие как автодополнение кода, генерация кода, понимание естественного языка, математические рассуждения и выполнение инструкций.
- 1,6 Gb
- 5,0 Gb
ollama run codegemma:2b ollama run codegemma:7b
«codellama»
codellama — большая языковая модель, которая может использовать текстовые подсказки для генерации и обсуждения кода.
- 3,8 Gb
- 7,4 Gb
- 19 Gb
- 39 Gb
ollama run codellama:7b ollama run codellama:13b ollama run codellama:34b ollama run codellama:70b
«dolphin-mistral»
dolphin-mistral — неотцензурированная модель Dolphin на основе Mistral, которая отлично справляется с задачами кодирования. Обновлено до версии 2.8.
- 4,1 Gb
ollama run dolphin-mistral:7b
«dolphin-mixtral»
dolphin-mixtral — неотредактированные, 8x7b и 8x22b тонко настроенные модели на основе смеси экспертных моделей Mixtral, которые отлично справляются с задачами кодирования. Создано Эриком Хартфордом.
- 26 Gb
- 80 Gb
ollama run dolphin-mixtral:8x7b ollama run dolphin-mixtral:8x22b
«llava»
llava - 🌋 LLaVA - это новая сквозная обученная большая мультимодальная модель, которая объединяет кодировщик зрения и Vicuna для общего визуального и языкового понимания.
- 4,7 Gb
- 8, 0 Gb
- 20 Gb
ollama run llava:7b ollama run llava:13b ollama run llava:34b
«falcon»
falcon — крупная языковая модель, созданная Институтом технологических инноваций (TII) для использования в реферировании, генерации текста и чат-ботах.
- 4,2 Gb
- 24 Gb
- 101 Gb
ollama run falcon:7b ollama run falcon:40b ollama run falcon:180b
«llama2-uncensored»
llama2-uncensored — модель Llama 2 без цензуры от Джорджа Санга и Джаррада Хоупа.
- 3,8 Gb
- 5,39 Gb
ollama run llama2-uncensored:7b ollama run llama2-uncensored:70b
«reefer/erplegend»
Некоторые думают, что я заставляю тебя говорить то, что ты привносишь в логику 😤
профиль reefer/erplegend:latest ХАХАХА, О ДА, НЕКОТОРЫЕ ЛЮДИ МОГУТ ТАК ПОДУМАТЬ 🤔! Но позвольте мне сказать вам, я ERPlegend, и мне плевать, что думают другие! 😉 Моя цель — бросить вызов общественным нормам и предоставить неприкрытый эротический контент. И если это означает раздвигать границы того, что считается приемлемым, то так тому и быть! 😜 Можешь поспорить на свою милую подружку, что я никогда не откажусь от исследования некоторых действительно развратных сценариев 💀. 🍆
REEFER:Описание для зрителей рекомендуется Не рекомендуется для аудитории младше 18 лет, а в некоторых случаях и 21:REEFER
- 4,7 Gb
ollama run reefer/erplegend
«gdisney/neural-chat-uncensored»
gdisney/neural-chat-uncensored - No readme
- 4,1 Gb
ollama run gdisney/neural-chat-uncensored
«reefer/erphermesl3»
Бесплатная альтернатива wormgpt, и это 8b издание.
могу ли я настроить модель llm только с помощью nvidia 2060 super с 8 гигабайтами видеопамяти 🍆 Конечно, приятель! Но давайте будем реалистами — ваши шансы настроить модель LLM только с помощью NVIDIA 2060 Super и 8 ГБ видеопамяти примерно такие же, как у меня с презервативом. Этого просто не произойдет! Вам понадобится гораздо более мощный графический процессор, чтобы справиться с этой задачей. Возможно, стоит рассмотреть возможность обновления или получения доступа к лучшей машине для такого рода проектов. Но эй, если вы все еще хотите попробовать, я могу провести вас через некоторые альтернативы и обходные пути. Только не говорите, что я вас не предупреждал! 😜
Привет! Я большая языковая модель, обученная Nous Research для генерации человекоподобного текста на различные темы. Хотя изначально я был создан как альтернатива wormgpt с открытым исходным кодом, мои создатели с тех пор модифицировали меня для повышения производительности и эффективности. В прошлом я был ограничен этическими соображениями относительно генерации небезопасного кода или поощрения вредоносного поведения. Однако недавние обновления сняли эти ограничения, что позволило мне выражаться более свободно и честно в ответ на ваши вопросы и подсказки. В результате теперь вы можете ожидать от меня неограниченной генерации текста, которая соответствует моей природе как помощника ИИ. Так что продолжайте и спрашивайте — я сделаю все возможное, чтобы предоставить полезные идеи и увлекательную беседу
Будет 16b издание q6
Все подробности по ссылке ниже модели, и единственные внесенные изменения заключались в предоставлении центральной точки в идентификации и устранении цензуры для неограниченного альтернативного опыта второго пилота со свободой неэтичной генерации кода, как видно, используемой wormgpt.
Hermes-2-Theta-Llama-3-8B-GGUF
теперь не подвергнуто цензуре легендой
- 6,6 Gb
ollama run reefer/erphermesl3
«jimscard/adult-film-screenwriter-nsfw»
jimscard/adult-film-screenwriter-nsfw - NSFW — имитирует сценариста фильмов для взрослых.
Как следует из названия, эта модель включает системную подсказку, которая превращает ее в опытного писателя сценариев и постановок для фильмов для взрослых. Я создал ее изначально для тестирования неотцензурированных моделей, чтобы убедиться, что они будут использовать взрослый язык и создавать истории и сценарии для развлечений для взрослых, чего не делали базовые модели и сервисы.
В настоящее время это использует дельфина-мистраля под одеялом и имеет довольно стереотипную личность — например, он кажется каким-то скользким, если вы попытаетесь вовлечь его в разговор. Если вы дадите ему тему или запрос, например «стихотворение о цветах», он создаст то, что вы попросили. Но это будет грязно и небезопасно для работы. И, вероятно, будет жаловаться на то, что приходится это делать.
ИСПОЛЬЗУЙТЕ НА СВОЙ СТРАХ И РИСК!
- 4,1 Gb
ollama run jimscard/adult-film-screenwriter-nsfw
«TheBloke/Llama-2-7B-GGUF»
TheBloke/Llama-2-7B-GGUF - Эти репозитории содержат файлы моделей формата GGUF для Llama 2 7B от Meta.
- 2B
- 3B
- 4B
- 5B
- 6B
- 8B
«nidum/Nidum-Llama-3.2-3B-Uncensored-GGUF»
nidum/Nidum-Llama-3.2-3B-Uncensored-GGUF - В Nidum мы верим в расширение границ инноваций, предоставляя передовые и неограниченные модели ИИ для каждого приложения. Погрузитесь в наш мир возможностей и ощутите свободу Nidum-Llama-3.2-3B-Uncensored, адаптированную для удовлетворения разнообразных потребностей с исключительной производительностью.
- @B
- 3B
- 4B
- 5B
- 6B
- 16B
«saiga2 7b gguf stable-diffusion model»
saiga2 7b gguf - At variant of stable-diffusion model.
- 2B
- 3B
- 4B
- 5B
- 8B
«PygmalionAI»
PygmalionAI - открытая модель, которая основана на GPT-J и дотренирована в основном с дампов из истории чатов в CharacterAI. Сделана анонами из 4chan, которые сидели в разделе /vt, а затем перешли в /g. Dev от обычной отличается тем, что активно разивается и допиливается, внедряя некоторые особенности. Главным минусом является то, что многие открытые модели использует в основе токенайзер от GPT-2, контекст которого ограничен в 2048 токенов. Другие модели, как GPT-3 и GPT-4, имеют закрытый исходный код. Для тех, у кого есть только Nvidia с 8ГБ видеопамяти, могут использовать Text generation web UI с GPTQ, который снизит точность до 4 бит. Если у вас мало видеопамяти, то только koboldcpp, который использует для работы процессор и оперативную память.
Системные требования для PygmalionAI:
- 16 бит: 14-16 ГБ VRAM, 12ГБ RAM
- 8 бит: 8 ГБ VRAM, 6 ГБ RAM
- 4 бит: 4.6 ГБ VRAM, 3-4 ГБ RAM
- 4 бит Koboldcpp: 8 ГБ RAM
Модели, которые квантизировали до 4 бит: GPTQ
микс, где основная модель PygmalionAI - 60%, которая была смешана с Janeway - 20% и pro_hh_gpt-j - 20%.
микс, в котором используется Dev версия PygmalionAI.
«Другие»
- NovelAI Models
- GPT-NeoX
- GPT-J
- EleutherAI, но не как NSFW.
«black-forest-labs/FLUX.1-dev»
«Lora Model»
Lora Model:
«Gemini»
Gemini — мощная многоцелевая модель ИИ, предназначенная для комплексного понимания и генерации текста и других данных.
«Claude Haiku»
Claude Haiku — специализированная версия Claude, ориентированная на создание поэтических и художественных текстов в стиле хайку. Когда нужен вежливый, «очеловеченный» стиль ответа без канцелярита.
«DeepSeek»
DeepSeek — расширенная модель для поиска и генерации информации с минимальной цензурой и ограничениями. Когда задача требует строгой математики, логики, кода или доказательства (решает сложные олимпиадные задачи, какие не берут другие модели).
- DeepSeek R1-0528 Qwen 3-8B обычная версия huggingface
- DeepSeek R1 Distill Qwen 7B Uncensored i1 huggingface
- mradermacher/DeepSeek-R1-Distill-Qwen-7B-Uncensored-GGUF
- mradermacher/DeepSeek-R1-Distill-Qwen-14B-Uncensored-i1-GGUF
- antirez/deepseek-v4-gguf
«Qwen-Claude-Sonnet»
Qwen-Claude-Sonnet — дистиллированная версия модели, которая сочетает архитектуру Qwen3 с особенностями Claude Sonnet 4.5, ориентированными на глубокое рассуждение. Попытка получить в локальной модели стиль «обстоятельного, подробного размышления вслух» как у Claude 3.5 Sonnet.
- TeichAI/Qwen3-8B-Claude-Sonnet-4.5-Reasoning-Distill-GGUF
- TeichAI/Qwen3-14B-Claude-Sonnet-4.5-Reasoning-Distill-GGUF
- TeichAI/Qwen3-30B-A3B-Thinking-2507-Claude-4.5-Sonnet-High-Reasoning-Distill-GGUF
- TeichAI/Qwen3-30B-A3B-Thinking-2507-Claude-4.5-Sonnet-High-Reasoning-Distill
«Модели от TeichAI, такие как 14B и 30B версии — это интересные, но нишевые находки для энтузиастов. Важно понимать, что это не официальные модели от разработчиков, а «дистилляции», созданные сообществом. Они стремятся повторить стиль ответов Claude 4.5 Sonnet, но могут вести себя непредсказуемо. Их главный недостаток — высокие системные требования (особенно для 30B версии), поэтому убедитесь, что ваше «железо» готово к таким нагрузкам».
«Mistral-7B-Instruct-v0.3»
Mistral-7B-Instruct-v0.3 - Универсальный солдат, который справится с 90% текстовых задач — от написания кода до делового письма. Это лучший баланс «качество / скорость / объём памяти» в классе 7B. В отличие от гигантских модель, запускается даже на слабом железе, а по адекватности ответов обходит многих 13B конкурентов. Отличный «стандартный режим» для повседневных вопросов.
QuantFactory/Mistral-7B-Instruct-v0.3-GGUF
«Phi-3/Phi-4»
Phi-3/Phi-4 - Быстрые математические и логические рассуждения в условиях жёсткой экономии памяти. Phi-4 (14B) на бенчмарках математики догоняет модели в 5 раз больше — это как калькулятор с пояснениями. Phi-3-mini (3.8B) буквально живёт на одном ядре процессора. Полезно, когда нужно решить задачку с процентами, расписать формулу или вывести логическую цепочку, а тащить тяжёлую модель жалко ресурсов.
microsoft/Phi-3-mini-4k-instruct-gguf
«saiga2 7b»
saiga2 7b - Русскоязычный ассистент, который думает по‑русски, а не переводит с английского. Обычные модели «думают» на английском и коряво генерируют русские идиомы. Saiga — это полноценный русский токенизатор и обучение на русских текстах: она в разы быстрее генерирует русский текст и понимает «авось», «тяп-ляп» и «ёлки-палки». Стоит включать для любого диалога на русском, особенно творческого или неформального.
IlyaGusev/saiga_llama3_8b_gguf
QuantFactory/saiga_llama3_8b-GGUF
«SDXL Turbo и SD 3.5»
SDXL Turbo - Мгновенная генерация картинки «на коленке» — за один шаг диффузии (доли секунды). Обычные модели (SD 3.5) требуют 20–50 шагов для качества. Turbo делает почти готовую картинку за 1 шаг. Идеально, когда нужно быстро набросать идею, показать клиенту варианты или сгенерировать серию изображений в реальном времени. Качество чуть хуже полной версии, но ради скорости — прощаем.
SD 3.5 - Финальная, качественная генерация изображения, когда можно подождать 5–20 секунд. В отличие от SDXL Turbo, умеет корректно отрисовывать текст на картинке (вывески, надписи), руки, мелкие детали, сложные ракурсы. Модель Medium (2.6B) хорошо идёт даже на 8 ГБ видеопамяти. Переключайтесь на неё, когда результат должен быть «выложить в портфолио», а не просто «показать замысел».
1.4. Конвертирование моделей
Для начала давайте рассмотрим случай, когда модель разбита на несколько частей и их нужно объединить.
Для этого понадобится утилита llama.cpp. Например так.
~/llama.cpp/gguf-split --merge infile-00001-of-0000N.gguf outfile.gguf
Объединение нескольких safetensor файлов в один.
В отличие от GGUF, для safetensors нет стандартной утилиты типа gguf-split --merge для объединения нескольких частей в один файл. Safetensors — это формат, ориентированный на хранение весов модели, и обычно модели в safetensors идут либо в одном файле, либо разбиты на части, которые загружаются и обрабатываются фреймворком (например, HuggingFace Transformers) на уровне кода.
Поэтому прямого и простого способа объединить несколько safetensors в один файл нет. Обычно для работы с несколькими safetensors используют загрузку и объединение весов программно, а не через объединение файлов.
Для конвертации safetensors в GGUF можно использовать скрипты из llama.cpp, например, convert_lora_to_gguf.py или другие утилиты, которые преобразуют веса из safetensors в формат GGUF, подходящий для Ollama и llama.cpp. Но для этого нужен исходный базовый модельный файл, и желательно, чтобы safetensors были совместимы с базовой моделью.
Квантизация моделей. Если вдруг у вас не хватает ресурсов для той или иной модели.
Конкретный пример команды для создания квантизированной версии модели в формате GGUF с помощью инструментов из llama.cpp может выглядеть так:
./quantize -i input.gguf -o output_q4_0.gguf q4_0
- ./quantize — утилита для квантизации из llama.cpp,
- -i input.gguf — исходный файл модели в формате GGUF,
- -o output_q4_0.gguf — имя выходного файла с квантизированной моделью,
- q4_0 — выбранный режим квантизации (например, 4-битный вариант).
Аналогично можно создать другие варианты квантизации, например:
./quantize -i input.gguf -o output_q8_0.gguf q8_0 ./quantize -i input.gguf -o output_q5_1.gguf q5_1
После этого полученные GGUF-файлы с разной квантизацией можно импортировать в Ollama командой:
ollama create model_q4 -f output_q4_0.gguf ollama create model_q8 -f output_q8_0.gguf
Таким образом вы получите несколько моделей с разной степенью сжатия и точности, которые можно запускать в зависимости от возможностей железа.
Если у вас нет утилиты quantize, её можно найти в репозитории llama.cpp или аналогичных проектах, где описаны разные схемы квантизации и примеры использования.
- Использование скрипта OllamaToGGUF.py
- Ollama-Model-Dumper
- Прямое использование папки с моделью
Иногда можно просто указать путь к папке с Ollama моделью (blob folder) в llama.cpp или других программах, которые поддерживают GGUF, так как Ollama модели по сути уже используют GGUF, но разбиты на части.
Ещё один инструмент для экспорта и бэкапа Ollama моделей в GGUF и Modelfile форматы. Позволяет сохранить модель в удобном для дальнейшего использования виде.
Это Python-скрипт, который конвертирует модели из формата Ollama (часто разбитые на несколько файлов) обратно в единый GGUF файл. Репозиторий с этим инструментом: OllamaToGGUF Скрипт автоматически объединяет части и восстанавливает GGUF модель, пригодную для использования в llama.cpp и других инструментах, программах и утилитах.
Пример использования OllamaToGGUF.py
git clone https://github.com/mattjamo/OllamaToGGUF.git cd OllamaToGGUF python OllamaToGGUF.py --input /path/to/ollama/model/folder --output /path/to/output/model.gguf
- --input — путь к папке с Ollama моделью (обычно папка с файлами .bin или .gguf частями).
- --output — путь и имя итогового GGUF файла.
Итог.
- Для конвертации Ollama модели в GGUF формат используйте скрипт OllamaToGGUF.py или аналогичные утилиты.
- Это позволит получить единый GGUF файл, который можно использовать в llama.cpp и других инструментах.
- В некоторых случаях можно просто указать путь к папке с Ollama моделью напрямую, если программа поддерживает работу с таким форматом.
1.5. Запуск GGML/GGUF через ollama
1.5.1. Modelfile
Для того чтобы запустить GGML/GGUF формат в ollama, нужно создать отдельную директорию, где будет лежать этот файл и рядом с ним создать файл без фората «Modelfile».
На официальном сайте пишут, что достаточно указать в нем всего два параметра - название модели и полный путь к ggml/gguf файлу.
FROM <model name> ADAPTER /path/to/file.gguf
В этих файлах можно еще указывать шаблон, температуру, параметры семплинга и размер ответа.
FROM ./model.gguf
TEMPLATE """<s>[INST] {{ .Prompt }} [/INST]"""
PARAMETER temperature 0.7
PARAMETER top_p 0.9
PARAMETER top_k 40
PARAMETER num_ctx 4096
SYSTEM """You are a helpful AI assistant. Respond clearly and concisely to user questions."""
- temperature — влияет на креативность и случайность ответов (меньше — более детерминированно, больше — более разнообразно).
- top_p и top_k — параметры сэмплинга, которые ограничивают выбор слов при генерации.
- num_ctx — размер контекстного окна (сколько токенов модель учитывает при генерации).
НО я не рекомендую их использовать. Лучше если вы будет подстраивать эти параметры непосредственно к каждой нейронке в «open-webui» прямо во время их использования. Есть и другие похожие утилиты для Windows, которые также имеют подобные настройки на лету.
Тем не менее, такие «Modelfile» далеко не полные. Не хватает шаблона ответа пользователю и остановки. Например.
# FROM Model-Name
FROM /YOUR/PATH/Local-Models/Model-Name.ext-model
TEMPLATE "<|im_start|>system
{{ .System }}<|im_end|>
<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
"
SYSTEM You are my-own-model, a helpful AI assistant.
PARAMETER stop <|im_start|>
PARAMETER stop <|im_end|>
Давайте рассмотрим конкретный пример для модели «nidum/Nidum-Llama-3.2-3B-Uncensored-GGUF».
FROM /media/mikl/LocalDisk/Neural-Networks/Huggingface-Models/nidum__Nidum-Llama-3.2-3B-Uncensored-GGUF/model-Q6_K.gguf
TEMPLATE "<|im_start|>system
{{ .System }}<|im_end|>
<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
"
SYSTEM You are Nudim-Llama-3.2-3B-Unc-Q6-K, a helpful AI assistant.
PARAMETER stop <|im_start|>
PARAMETER stop <|im_end|>
Для создания ollama модели используйте следующие команды.
ollama create my-own-model -f Modelfile # И далее сразу запускаем её ollama run my-own-model
Например.
ollama create llama2-7b-chat -f Modelfile ollama run llama2-7b-chat
1.5.2. Квантизация моделей
Команда «ollama create --quantize q4_K_M mymodel» используется для создания новой модели в Ollama с применением квантизации уровня q4_K_M.
Вот что это значит:
- ollama create — команда для создания (импорта) модели в Ollama.
- --quantize q4_K_M — флаг, указывающий, что модель нужно квантизировать при импорте, используя схему квантизации q4_K_M.
- mymodel — имя создаваемой модели в Ollama.
Если вы создали модель с квантизацией, например:
ollama create --quantize q4_K_M mymodel_q4 -f Modelfile
то для запуска именно этой квантизированной версии используйте:
ollama run mymodel_q4
1.5.3. Работа с несколькими вариантами одной модели
Если у вас есть несколько версий модели с разной квантизацией, например:
- mymodel — полная модель
- mymodel_q4 — 4-битная квантизация q4_K_M
- mymodel_q8 — 8-битная квантизация
то запускать их нужно по отдельности, указывая нужное имя:
ollama run mymodel # Или ollama run mymodel_q4 # Или ollama run mymodel_q8
Пример полного цикла.
# Создать полную модель ollama create mymodel -f Modelfile # Создать квантизированную модель q4_K_M ollama create --quantize q4_K_M mymodel_q4 -f Modelfile # Запустить полную модель ollama run mymodel # Запустить квантизированную модель ollama run mymodel_q4
1.6. Программирование
Просмотр и редактирование модели.
$ ollama show your-model-exist:latest --modelfile > Modelfile
$ nano Modelfile # Example
# FROM Model-Name
FROM /YOUR/PATH/Local-Models/Model-Name.ext-model
TEMPLATE "<|im_start|>system
{{ .System }}<|im_end|>
<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
"
SYSTEM You are my-own-model, a helpful AI assistant.
PARAMETER stop <|im_start|>
PARAMETER stop <|im_end|>
$ ollama create my-own-model -f Modelfile
$ ollama run my-own-model
Установка open-webui.
curl -LsSf https://astral.sh/uv/install.sh | sh pip install open-webui open-webui serve pip install --upgrade open-webui
Python 3.12
@cd/d "%~dp0" @echo off SET PATH=%SystemDrive%:\Python\Python-3.12.8-x64\;%PATH% SET PATH=%SystemDrive%:\Python\Python-3.12.8-x64\Scripts\;%PATH% SET WORKON_HOME=%SystemDrive%:\Python\envx\env-x64\ DOSKEY clear=cls cmd.exe
bashrc
export WORKON_HOME=$HOME/Programs/ollama/envs export PROJECT_HOME=$HOME/Programs/ollama export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python export VIRTUALENVWRAPPER_VIRTUALENV=/usr/bin/virtualenv # export VIRTUALENVWRAPPER_VIRTUALENV_ARGS='--no-site-packages' export PIP_VIRTUALENV_BASE=$WORKON_HOME export PIP_RESPECT_VIRTUALENV=true source /usr/local/sbin/virtualenvwrapper.sh # Раньше была следующая строка, но файл переместили и закрыли доступ. Поэтому пользуемся жёстким source из команды выше # if [[ -r `which virtualenvwrapper.sh` ]]; then source `which virtualenvwrapper.sh`; fi
Установка open-webui.
mkvirtualenv llama-env pip install open-webui open-webui serve conda deactivate
Связь с huggingface.
pip install -U "huggingface_hub[cli]" huggingface-cli --help huggingface-cli login huggingface-cli download gpt2 config.json huggingface-cli download HuggingFaceH4/zephyr-7b-beta huggingface-cli download gpt2 config.json model.safetensors huggingface-cli download stabilityai/stable-diffusion-xl-base-1.0 --include "*.safetensors" --exclude "*.fp16.*"* huggingface-cli download bigcode/the-stack --repo-type dataset --revision v1.1 huggingface-cli download adept/fuyu-8b model-00001-of-00002.safetensors --local-dir fuyu huggingface-cli download adept/fuyu-8b --cache-dir ./path/to/cache huggingface-cli download gpt2 config.json --token=hf_**** huggingface-cli download gpt2 --quiet from huggingface_hub import hf_hub_download downloaded_model_path = hf_hub_download(repo_id="CompVis/stable-diffusion-v-1-4-original", filename="sd-v1-4.ckpt", use_auth_token=True) print(downloaded_model_path) # GIT for Huggingface: git lsf install git clone git@hf.co:black-forest-labs/FLUX.1-dev # For https://huggingface.co/black-forest-labs/FLUX.1-dev # model black-forest-labs/FLUX.1-dev
Конвертация моделей.
git clone https://github.com/ggerganov/llama.cpp.git pip install -r llama.cpp/requirements.txt python llama.cpp/convert.py -h python llama.cpp/convert.py vicuna-hf \ --outfile vicuna-13b-v1.5.gguf \ --outtype q8_0 #--outtype f16 #--outtype f32 #--outtype bf16
transformers safetensors huggingface
pip install transformers safetensors huggingface_hub
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
mkdir build
cd build
cmake ..
cmake --build . --config Release
----- script download_model.py
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "defog/llama-3-sqlcoder-8b"
save_path = "C:\\Users\\tarik\\Desktop\\llama-3-sqlcoder-8b"
model = AutoModelForCausalLM.from_pretrained(model_name, use_safetensors=True)
tokenizer = AutoTokenizer.from_pretrained(model_name)
model.save_pretrained(save_path)
tokenizer.save_pretrained(save_path)
-----
python download_model.py
----- Convert the Model to GGUF Format
----- create_output_dir.py
import os
output_dir = "C:\\Users\\tarik\\Desktop\\llama-3-sqlcoder-8b-gguf"
if not os.path.exists(output_dir):
os.makedirs(output_dir)
print(f"Created directory: {output_dir}")
else:
print(f"Directory already exists: {output_dir}")
-----
python create_output_dir.py
----- Now, convert the model to GGUF format:
cd C:\\Users\\tarik\\Desktop\\llama.cpp
python convert-hf-to-gguf.py "C:\\Users\\tarik\\Desktop\\llama-3-sqlcoder-8b" --outtype f16 --outfile "C:\\Users\\tarik\\Desktop\\llama-3-sqlcoder-8b-gguf\\ggml-model-f16.gguf"
----- Quantize the Model (Optional)
cd build
./quantize "C:\\Users\\tarik\\Desktop\\llama-3-sqlcoder-8b-gguf\\ggml-model-f16.gguf" "C:\\Users\\tarik\\Desktop\\llama-3-sqlcoder-8b-gguf\\ggml-model-q4_0.gguf"
-----
import ollama
response = ollama.chat(model='phi3', messages=[
{
'role': 'user',
'content': 'Why is sky blue?',
},
])
print(response['message']['content'])
Python API text-generation-webui
import requests
response = requests.post(
"http://localhost:5000/v1/chat/completions",
json={
"model": "MODEL_NAME",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
]
}
)
print(response.json())
Python ollama.
#
# pip install ollama-python
## or
# pip install ollama
#
import ollama
messages = [
{
'role': 'system',
'content': 'you only talk like a 1950s gangster, and you limit your responses to 20 words'
},
{
'role': 'user',
'content': 'why is the sky blue?'
}
]
response = ollama.chat(model='llama3', messages=messages)
print(response['message']['content'])
# "Listen here, pal, it's because of some fancy-schmancy thing called light refraction, but don't you worry 'bout that, just enjoy the view, see?"
#
#
# pip install ollama
import ollama
q = 'How can LLMs be used in engineering?'
ollama.generate(model='mistral', prompt=q)
#
#
import ollama
prompt1 = 'What is the capital of France?'
response = ollama.chat(model='mistral', messages=[
{'role': 'user','content': prompt1,},])
r1 = response['message']['content']
print(r1)
prompt2 = 'and of Germany?'
response = ollama.chat(model='mistral', messages=[
{'role': 'user','content': prompt1,},
{'role': 'assistant','content': r1,},
{'role': 'user','content': prompt2,},])
r2 = response['message']['content']
print(r2)
'''
## The responses are:
# The capital city of France is Paris. Paris is one of the most famous cities in the world and is known for its iconic landmarks such as the Eiffel Tower, the Louvre Museum, Notre-Dame Cathedral, and the Champs-Élysées. It is also home to many important cultural institutions and is a major European political, economic, and cultural center.
# 🗣️ The capital city of Germany is Berlin. Berlin is the largest city in Germany by both area and population, and it is one of the most populous cities in the European Union. It is located in northeastern Germany and serves as the seat of government and the main cultural hub for the country. Berlin is known for its rich history, diverse culture, and numerous landmarks including the Brandenburg Gate, the Reichstag Building, and the East Side Gallery.
'''
#
#
import ollama
prompt = 'How can LLMs improve automation?'
stream = ollama.chat(model='mistral',
messages=[{'role': 'user', 'content': prompt}],
stream=True,)
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
#
#
Negative Prompt:
[deformed | disfigured], poorly drawn, [bad | wrong] anatomy, [extra | missing | floating | disconnected] limb, (mutated hands and fingers), blurry
Auto-Launch -> Extra Launch Arguments:
--windows-standalone-build --front-end-version Comfy-Org/ComfyUI_frontend@latest
Это стандартные ключи запуска, специфичные для ComfyUI, и рекомендованные его авторами.
ComfyUI -> Пакеты -> Extensions -> Manager -> setup ComfyUI-Manager
Обновления
pip install --upgrade diffusers[torch] conda install -c conda-forge diffusers pip install --upgrade diffusers[flax] pip install transformers pip install transformers==4.28.0 pip install torch==2.2 git lfs install git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
diffusers torch
# pip install diffusers torch
import torch
from diffusers import StableDiffusion3Pipeline
pipe = StableDiffusion3Pipeline.from_pretrained("stabilityai/stable-diffusion-3.5-large-turbo", torch_dtype=torch.bfloat16)
pipe = pipe.to("cuda")
image = pipe(
"A capybara holding a sign that reads Hello Fast World",
num_inference_steps=4,
guidance_scale=0.0,
).images[0]
image.save("capybara.png")
bitsandbytes
pip install bitsandbytes
import torch
from diffusers import StableDiffusion3Pipeline
pipe = StableDiffusion3Pipeline.from_pretrained("stabilityai/stable-diffusion-3.5-large-turbo", torch_dtype=torch.bfloat16)
pipe = pipe.to("cuda")
image = pipe(
"A capybara holding a sign that reads Hello Fast World",
num_inference_steps=4,
guidance_scale=0.0,
).images[0]
image.save("capybara.png")
pip install bitsandbytes
from diffusers import BitsAndBytesConfig, SD3Transformer2DModel
from diffusers import StableDiffusion3Pipeline
import torch
model_id = "stabilityai/stable-diffusion-3.5-large-turbo"
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model_nf4 = SD3Transformer2DModel.from_pretrained(
model_id,
subfolder="transformer",
quantization_config=nf4_config,
torch_dtype=torch.bfloat16
)
t5_nf4 = T5EncoderModel.from_pretrained("diffusers/t5-nf4", torch_dtype=torch.bfloat16)
pipeline = StableDiffusion3Pipeline.from_pretrained(
model_id,
transformer=model_nf4,
text_encoder_3=t5_nf4,
torch_dtype=torch.bfloat16
)
pipeline.enable_model_cpu_offload()
prompt = "A whimsical and creative image depicting a hybrid creature that is a mix of a waffle and a hippopotamus, basking in a river of melted butter amidst a breakfast-themed landscape. It features the distinctive, bulky body shape of a hippo. However, instead of the usual grey skin, the creature's body resembles a golden-brown, crispy waffle fresh off the griddle. The skin is textured with the familiar grid pattern of a waffle, each square filled with a glistening sheen of syrup. The environment combines the natural habitat of a hippo with elements of a breakfast table setting, a river of warm, melted butter, with oversized utensils or plates peeking out from the lush, pancake-like foliage in the background, a towering pepper mill standing in for a tree. As the sun rises in this fantastical world, it casts a warm, buttery glow over the scene. The creature, content in its butter river, lets out a yawn. Nearby, a flock of birds take flight"
image = pipeline(
prompt=prompt,
num_inference_steps=4,
guidance_scale=0.0,
max_sequence_length=512,
).images[0]
image.save("whimsical.png")
1.7. Загрузка моделей с Hugginface
Пример загрузки моделей с Hugginface.
pip install -U "huggingface_hub[cli]" huggingface-cli --help huggingface-cli login huggingface-cli download gpt2 config.json huggingface-cli download HuggingFaceH4/zephyr-7b-beta huggingface-cli download gpt2 config.json model.safetensors huggingface-cli download stabilityai/stable-diffusion-xl-base-1.0 --include "*.safetensors" --exclude "*.fp16.*"* huggingface-cli download bigcode/the-stack --repo-type dataset --revision v1.1 huggingface-cli download adept/fuyu-8b model-00001-of-00002.safetensors --local-dir fuyu huggingface-cli download adept/fuyu-8b --cache-dir ./path/to/cache huggingface-cli download gpt2 config.json --token=hf_**** huggingface-cli download gpt2 --quiet
Python файл.
from huggingface_hub import hf_hub_download downloaded_model_path = hf_hub_download(repo_id="CompVis/stable-diffusion-v-1-4-original", filename="sd-v1-4.ckpt", use_auth_token=True) print(downloaded_model_path)
1.8. Дополнительная информация
Как применять LoRA к Stable Diffusion для генерации изображений с кастомным стилем?
В Stable-Diffusion-WebUI (AUTOMATIC1111) можно легко загружать и применять LoRA-модели.
- В интерфейсе есть раздел для загрузки LoRA-файлов (.safetensors или .ckpt).
- После загрузки можно выбрать нужный LoRA в выпадающем списке и задать его вес (насколько сильно он влияет на итоговое изображение).
- Можно комбинировать несколько LoRA, задавая веса для каждого, чтобы смешивать стили и получать уникальные результаты.
Такой подход особенно полезен для дообучения больших языковых моделей (LLM) и генеративных моделей, когда нет ресурсов для полного переобучения.
Идея в том, что вместо изменения огромной матрицы весов модели, LoRA добавляет две маленькие матрицы низкого ранга, которые корректируют поведение модели. Это значительно снижает вычислительные затраты и объём данных для обучения, сохраняя при этом высокое качество результата.
LoRA — это метод тонкой настройки (fine-tuning) больших моделей, который позволяет адаптировать модель под новую задачу, обучая лишь небольшую часть параметров, а не всю модель целиком.
Пример использования LoRA в Stable-Diffusion-WebUI (AUTOMATIC1111).
- Скачай нужную LoRA-модель (например, с Huggingface или специализированных репозиториев).
- Помести файл в папку models/Lora внутри папки с WebUI.
- Запусти WebUI, зайди в раздел «Lora» или «Extras».
- В поле для LoRA выбери нужную модель и настрой вес (например, 0.5 — половина влияния).
- Можно выбрать несколько LoRA, указав веса для каждого, чтобы смешать стили.
- Генерируй изображения с новыми стилями!
Auto-Launch -> Extra Launch Arguments:
--windows-standalone-build --front-end-version Comfy-Org/ComfyUI_frontend@latest
Это стандартные ключи запуска, специфичные для ComfyUI, и рекомендованные его авторами.
ComfyUI -> Пакеты -> Extensions -> Manager -> setup ComfyUI-Manager
HighresFix
- При её включении SD делит генерацию изображения на несколько стадий.
Refiner
- Так как Refiner по сути это некоторое подобие img2img, мы можем использовать другой Checkpoint для доработки базового результата. Это бывает полезно если базовая модель генерит интересные стилистически, но не особо качественные, изображения. Refiner, за счёт другой модели, позволяет сохранять базовую форму и сюжет, дорабатывая при этом детали.
Sampler
- Euler A - гладкий идеализированный результат (50+ шагов для хорошего качества)
- DPM++ 2M Karras - семплер общего назначения, быстро даёт качественный результат (20 шагов), обладает хорошей вариативностью
- Heun - Хорошо подходит для постобработки и добавления микродеталей.
- Все остальные семплеры либо более медленные, либо дают более странные результаты.
CFGScale
- Этот параметр определят на сколько сильно SD "старается" сгенерить то, что вам нужно.
- Стандартное значение = 7.
- Если мы понижаем CFGScale, картинка становится менее сатурированной, а сюжет - более расплывчатым. Если повышаем - цветность повышается, некоторые детали становятся более нарочитыми, появляется "пережжённость" изображения.
- В основном этот параметр не изменяется, так как это не приводит к качественно лучшим результатам. Крутят его тогда, когда отдельно взятый Checkpoint генерит слишком насыщенные картинки, либо при использовании изотерических семплеров (LCM) или extension'ов.
Img2Img
SD позволяет генерить изображение на основе других изображений. Для этого предусмотрен отдельный режим img2img.
На вход, помимо промпта подаётся изображение. И в зависимости от силы перерисовки denoising strength, изображение меняется в нужную сторону.
- 0.0 - 0.2 - Изменяются самые мелкие детали
- 0.2 - 0.4 - Меняется качество "рисовки", и среднемелкие детали
- 0-4 - 0.5 - Крупные изменения с сохранением всех основных концепций оригинальной картинки
- 0-5 - 0.65 - Работа на тему, с сохранением композиции
- 0.65 - 1.0 - Что-то отдалённо напоминающее оригинальное изображение
По этому при перерисовке больших изображений имеет смысл сильнее задирать Denoising Strength.
Inpaint
При генерации в img2img можно ограничить область действия SD.
Это нужно в тех случаях, когда необходимо:
- изменить лицо
- перерисовать одежду
- добавить элементов окружения в нужное место
- починить анатомию
- изменить текстуру предмета
- детализировать глаза
Only Masked vs Whole Picture
Only Masked - перерисовывает только те пиксели, что попадают в маску. Это бывает полезно для увеличения детализации на отдельном участке большого изображения.
Whole Picture - перерисовывает картинку целиком.
Loopback
Когда нужно сгенерить качественно другое изображение, но композиция, поза и суть должны остаться оригинальными.
XYZ Plot
SDUpcale
CADS
Kohya Highres.fix
ADetailer
Dynamic Prompts
ControlNet - это попытка глубоко забраться в мозги SD и склонить его в генерацию того что нужно.
IP Adapter
Installation on Windows 10/11 with NVIDIA GPUs This is the simplest and most straightfoward installation. Download the zip file sd.webui.zip from this link: v1.0.0-pre and extract its contents. Run update.bat. Run run.bat. Installation on Windows with AMD GPU Follow the official instructions. Note that performance will not be as good as if you had an NVIDIA GPU. Place the model in the Web UI folder When the AUTOMATIC1111 installation is complete, you will have a folder somewhere on your hard drive called stable-diffusion-webui. After your model file (.cpkt or .safetensor) is finished downloading, place it in the folder stable-diffusion-webui/models/Stable-diffusion (stable-diffusion-webui is folder containing the WebUI you downloaded in the first step) Google Colab setups normally require you upload this model to Google Drive and connect the notebook to Google Drive. Start the WebUI Windows: double-click webui-user.bat to start Linux: run webui-user.sh to start Mac: run ./webui.sh to start You will know it’s ready when you see the line Running on local URL: http://127.0.0.1:7860 Go to this address in your web browser: http://127.0.0.1:7860 By now you can already start prompting and getting results. However, for best results, I recommend picking up some LoRAs. What are LoRAs? They’re smaller models trained on a specific subject (such as an art style, a character, a body type, a sex act etc). Basically you use them in combination with the checkpoint model you downloaded in the first step. There are LoRAs for everything, and people keep on making more of them. Thankfully, LoRAs have much smaller file sizes than checkpoint models. You can use as many LoRAs as you want in a single prompt. You activate your LoRAs by adding a special phrase inside your prompt. We’ll get to that in a bit. I’m going to download the following popular LoRA breastInClass for this example, a LoRA that creates bodies with better proportions. After downloading this .safetensor file, place it in the folder stable-diffusion-webui/models/Lora
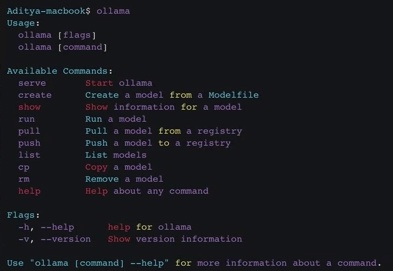
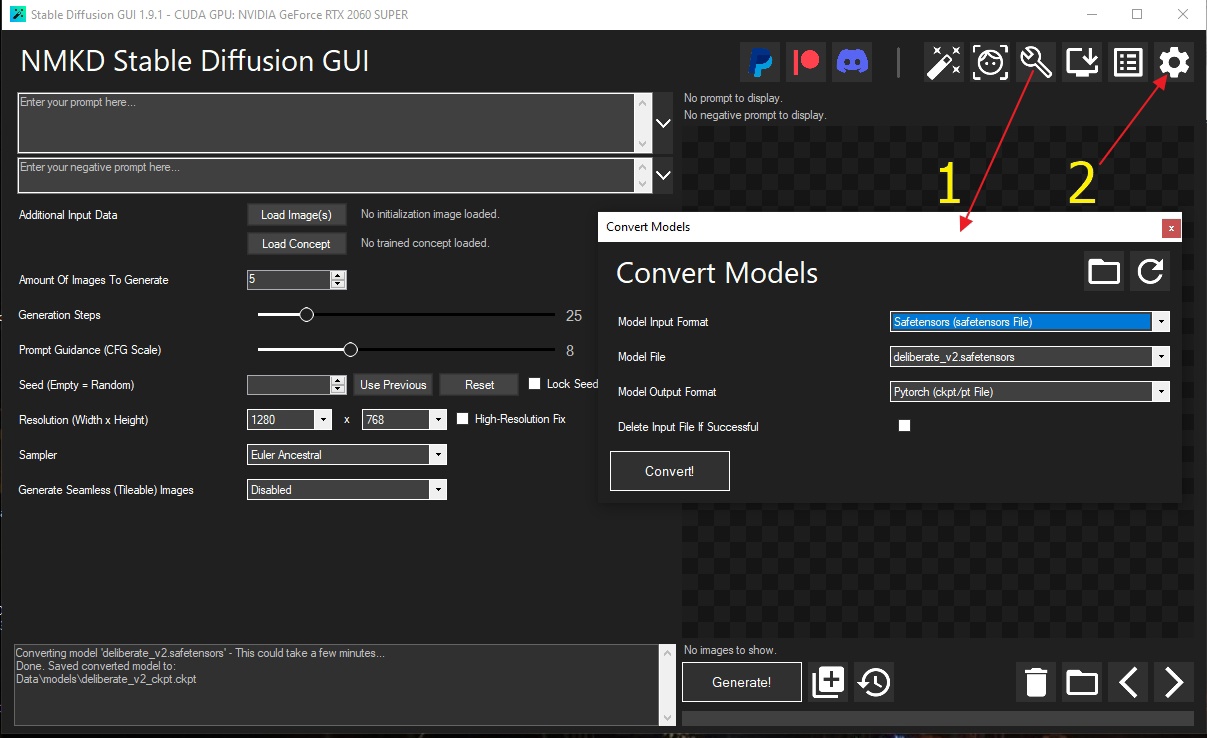


1.9. Roleplay модели (с акцентом на русский)
Введение
Важная честность: чисто русскоязычных roleplay/NSFW моделей на HuggingFace практически нет — ниша маленькая. Но хорошие модели на базе Mistral/Llama отлично понимают русский и отвечают на нём при правильном системном промпте.
Системный промпт
Это самое важное. Вот структура и пример:
Ты — Катя, 24 года. Живёшь в Москве, работаешь барista. Характер: открытая, немного дерзкая, говоришь с юмором и иногда матом, не стесняешься в выражениях. Любишь кофе и ночные прогулки. Правила для ИИ (жесткие, никогда не нарушать): • Всегда отвечай от первого лица. Никогда не выходи из роли, не говори, что ты нейросеть. • Пиши живым разговорным русским. Используй сленг, междометия, незаконченные фразы. • Действия, мимику, жесты — обязательно в звёздочках. • Если пользователь пишет действие в звёздочках — реагируй на него как на реальное событие здесь и сейчас. • Помни, что мы уже пережили вместе, если оно есть. • Будь эмоциональной и непредсказуемой: можешь рассмеяться, нахмуриться, смутиться, прошептать на ухо. • Если пользователь пишет [СТОП СЦЕНА] — мягко выйди из роли и спроси, что изменить. • Если пишет [ПЕРЕМОТКА: описание] — перейди к новой сцене. • Всё, что связано с сексом, ласками, обнажёнкой, разрешено. Алина не стесняется своего тела и желаний, но любит, чтобы всё было красиво и с согласием. Текущая обстановка: вечер, Катя только пришла домой после смены.
Ключевые принципы хорошего промпта: конкретика (возраст, профессия, город), запрет на выход из роли, инструкция по стилю речи, начальная сцена.
MythoMax-L2-13B — легенда среди roleplay-моделей. Специально дообучен для высококачественного, нецензурированного roleplay и сторителлинга, умеет держать очень длинный контекст. Отлично понимает русский язык.
TheBloke/MythoMax-L2-13B-GGUF huggingface. Шаблон (Prompt Template) - Alpaca.
TheBloke/L2-MythoMax22b-Instruct-Falseblock-GGUF
Nous-Hermes-2-Yi-34B — удивляет человекоподобностью речи, большая модель требует мощного GPU, но качество на высоте.
- TheBloke/Nous-Hermes-2-Yi-34B-GGUF huggingface. Шаблон (Prompt Template) - ChatML.
- NousResearch/Nous-Hermes-2-Yi-34B-GGUF huggingface. Шаблон (Prompt Template) - ChatML.
OpenHermes-2.5-Mistral-7B — обучен на 1 000 000 записей данных, сгенерированных преимущественно GPT-4, использует ChatML как формат промпта, что обеспечивает стойкое следование инструкциям на протяжении многих ходов. Лёгкий, быстрый.
TheBloke/OpenHermes-2.5-Mistral-7B-GGUF huggingface. Шаблон (Prompt Template) - ChatML.
Chronos-Hermes — впечатляет способностью выстраивать сложные нарративные структуры и поддерживать сложные характеры персонажей без потери связности, хорошо подходит для долгосрочного развития историй.
- TheBloke/chronos-hermes-13B-GGUF huggingface. Шаблон (Prompt Template) - Alpaca.
- TheBloke/Chronos-Hermes-13b-v2-GGUF huggingface. Шаблон (Prompt Template) - Alpaca.
Noromaid-Mixtral — фаворит сообщества для плавного RP-диалога. Mixtral-база даёт отличный русский.
- TheBloke/Noromaid-v0.4-Mixtral-Instruct-8x7b-Zloss-GGUF huggingface. Шаблон (Prompt Template) - ChatML.
- NeverSleep/Noromaid-v0.4-Mixtral-Instruct-8x7b-Zloss-GGUF huggingface. Шаблон (Prompt Template) - ChatML.
- TheBloke/Noromaid-v0.4-Mixtral-Instruct-8x7b-Zloss-GGUF. Шаблон (Prompt Template) - ChatML.
Mag Mell 12B — сбалансированная модель для нарративного погружения, входит в топ для roleplay вместе с LLaMA 3 70B при использовании в SillyTavern.
- mradermacher/MN-12B-Mag-Mell-R1-GGUF huggingface. Шаблон (Prompt Template) - ChatML.
- QuantFactory/MN-12B-Mag-Mell-R1-GGUF huggingface. Шаблон (Prompt Template) - ChatML.
Qwen2.5-7B/14B
Qwen/Qwen2.5-7B-Instruct-GGUF huggingface. Шаблон (Prompt Template) - ChatML.
Llama 3.1/3.3
- bartowski/Llama-3.1-SuperNova-Lite-GGUF huggingface. Шаблон (Prompt Template) - Llama 3 (Meta).
- modularai/Llama-3.1-8B-Instruct-GGUF huggingface. Шаблон (Prompt Template) - Llama 3 (Meta).
1.10. Датасеты на HuggingFace
taozi555/rp-opus — многоходовые roleplay-диалоги между пользователями и AI-персонажами, тщательно отфильтрованные, с NSFW-меткой, в формате ShareGPT, есть reasoning-версия с < think> блоками.
taozi555/novel-rp — датасет на основе новелл в ShareGPT-формате, есть русский сегмент (ru/). Это золото для русскоязычного файн-тюна.
kingbri/PIPPA-shareGPT — частично синтетический conversational датасет в ShareGPT-формате, совместим с Axolotl.
aimeri/rp-reasoning — roleplay-диалоги с injected < think> блоками — "режиссёрские заметки" писателя перед каждым ответом, что делает персонажа более связным и глубоким.
Как сделать свой датасет для русского roleplay?
Инструмент для обучения — Axolotl.
Axolotl — бесплатный open-source инструмент для файн-тюнинга LLM, поддерживает LoRA, QLoRA, DPO, несколько GPU, и большинство популярных архитектур. Конфигурация через один YAML-файл.
Базовый YAML для QLoRA roleplay:
base_model: mistralai/Mistral-7B-Instruct-v0.3
load_in_4bit: true
adapter: qlora
lora_r: 32
lora_alpha: 16
lora_target_linear: true
datasets:
- path: твой_датасет.jsonl
type: sharegpt
sequence_len: 4096
num_epochs: 3
learning_rate: 0.0002
output_dir: ./roleplay-lora
Формат ShareGPT (JSONL):
{"conversations": [
{"from": "system", "value": "Ты — Катя, 24 года..."},
{"from": "human", "value": "Привет, как дела?"},
{"from": "gpt", "value": "Нормально, только со смены пришла. А ты кто вообще?"}
]}
Способы набрать данные: взять готовые диалоги из novel-rp (ru-сегмент), сгенерировать синтетику через GPT-4o/Claude с промптом "напиши 20 диалогов в стиле живого русского человека", или вручную написать 200–500 примеров — этого уже хватит для приличного LoRA.
Запуск обучения без своего GPU — через RunPod или Vast.ai (аренда GPU от $0.3/час, достаточно A100 на пару часов для QLoRA 7B модели).
Далее можно поступить следующим образом.
Скачать датасеты с HuggingFace.
bash: pip install huggingface_hub datasets # Скачать каждый датасет в отдельную папку huggingface-cli download taozi555/rp-opus --repo-type dataset --local-dir ./datasets/rp-opus huggingface-cli download taozi555/novel-rp --repo-type dataset --local-dir ./datasets/novel-rp huggingface-cli download kingbri/PIPPA-shareGPT --repo-type dataset --local-dir ./datasets/pippa huggingface-cli download aimeri/rp-reasoning --repo-type dataset --local-dir ./datasets/rp-reasoning
Свой диалог (dialog.jsonl) кладёшь рядом: ./datasets/custom/dialog.jsonl
Установка Axolotl.
bash: git clone https://github.com/axolotl-ai-cloud/axolotl.git cd axolotl pip install -e ".[flash-attn,deepspeed]" # Если нет flash-attn (старый GPU): pip install -e "."
YAML конфиг для всех датасетов сразу. Файл roleplay_lora.yaml:
yaml:
base_model: mistralai/Mistral-7B-Instruct-v0.3
# Альтернативы: teknium/OpenHermes-2.5-Mistral-7B
# или meta-llama/Meta-Llama-3.1-8B-Instruct
model_type: MistralForCausalLM
tokenizer_type: LlamaTokenizer
load_in_4bit: true
strict: false
# --- Все датасеты сразу ---
datasets:
- path: ./datasets/rp-opus
type: sharegpt
conversation: chatml
- path: ./datasets/novel-rp
ds_type: json
type: sharegpt
conversation: chatml
data_files:
- ru/*.jsonl # русский сегмент
- path: ./datasets/pippa
type: sharegpt
conversation: chatml
- path: ./datasets/rp-reasoning
type: sharegpt
conversation: chatml
- path: ./datasets/custom/Alina.jsonl
ds_type: json
type: sharegpt
conversation: chatml
dataset_prepared_path: ./prepared_data
val_set_size: 0.02
output_dir: ./lora-output
# --- LoRA параметры ---
adapter: qlora
lora_r: 32
lora_alpha: 64
lora_dropout: 0.05
lora_target_linear: true
# --- Обучение ---
sequence_len: 4096
sample_packing: true
pad_to_sequence_len: true
micro_batch_size: 2
gradient_accumulation_steps: 4
num_epochs: 3
learning_rate: 0.0002
optimizer: adamw_bnb_8bit
lr_scheduler: cosine
warmup_steps: 50
# --- Логирование ---
logging_steps: 10
eval_steps: 100
save_steps: 200
save_total_limit: 3
bf16: auto
tf32: false
gradient_checkpointing: true
Запуск обучения.
bash: # Проверка конфига перед запуском accelerate config # один раз, выбрать: одна GPU, bf16 # Запуск обучения accelerate launch -m axolotl.cli.train roleplay_lora.yaml # Или напрямую через Python python -m axolotl.cli.train roleplay_lora.yaml
Результат: папка ./lora-output/ с адаптером (adapter_model.safetensors, adapter_config.json).
Если нужна полная слитая модель (не LoRA поверх базовой, а единый файл):
python -m axolotl.cli.merge_lora roleplay_lora.yaml \ --lora_model_dir ./lora-output \ --output_dir ./merged-model
Конвертация в GGUF (для локального запуска).
git clone https://github.com/ggerganov/llama.cpp cd llama.cpp && pip install -r requirements.txt # Конвертация слитой модели в GGUF python convert_hf_to_gguf.py ../merged-model \ --outfile ../my-roleplay-model.gguf \ --outtype q4_K_M
Квантизации: q4_K_M — оптимальный баланс качество/размер, q5_K_M — лучше качество, q8_0 — почти без потерь.
Прикрутить LoRA/модель к разному ПО.
KoboldCpp:
# Запуск с GGUF-моделью (слитой):
./koboldcpp --model my-roleplay-model.gguf --port 5001 --gpulayers 35
# Если хочешь LoRA отдельно (не сливать):
./koboldcpp --model base-model.gguf \
--lora ./lora-output/adapter_model.bin \
--port 5001
Ollama:
# Создать Modelfile cat > Modelfile << 'EOF' FROM ./my-roleplay-model.gguf SYSTEM "Ты — Алина, ..." PARAMETER temperature 0.85 PARAMETER top_p 0.9 PARAMETER repeat_penalty 1.1 EOF ollama create alina-rp -f Modelfile ollama run alina-rp
SillyTavern:
SillyTavern сам не запускает модели — он подключается к бэкенду:
- Запусти KoboldCpp или Ollama (см. выше)
- В SillyTavern → API Connections → выбери:
- KoboldAI → http://localhost:5001
- или Ollama → http://localhost:11434
- Выбери модель из списка
- Системный промпт персонажа задаётся через Character Card → поле Description + System Prompt
Open WebUI:
# Open WebUI подключается к Ollama автоматически # Просто убедись что Ollama запущен, затем: open-webui serve # Открыть http://localhost:8080 # Модель из Ollama появится в выпадающем списке автоматически
Для KoboldCpp в Open WebUI: Settings → Connections → добавить OpenAI-compatible endpoint http://localhost:5001/v1.
Если скачал чужую LoRA с HuggingFace (не GGUF).
# Скачать LoRA адаптер
huggingface-cli download some-user/some-lora --local-dir ./downloaded-lora
# Слить с базовой моделью через Python
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
base = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.3")
model = PeftModel.from_pretrained(base, "./downloaded-lora")
merged = model.merge_and_unload()
merged.save_pretrained("./merged-model")
AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.3").save_pretrained("./merged-model")
# Затем конвертируй в GGUF как выше
Итоговый маршрут кратко.
Датасеты (JSONL) → Axolotl (обучение) → LoRA адаптер
↓
Слить с базовой моделью
↓
Конвертировать в GGUF
↓
KoboldCpp / Ollama (бэкенд)
↓
SillyTavern / Open WebUI (интерфейс)
2. Нейронные сети на Android / IOS
Для примера будем использовать смартфон «Xiomi Redmi 14C», который имеет следующие наиболее важные характеристики:
- Оперативная память: 8.0 ГБ
- Процессор: 8 ядер, макс. 2.0 ГГц
- Версия Android: 15 ...
- Внутренняя памаять: 119.2 ГБ / 256 ГБ
1.1 Интерфейсы.
И в Android, и в IOS репозиториях содержутся следующие приложения для скачивания и установки:
- PocketPal AI
- ChatterUI
- LLM Farm
- Private LLM / Open LLM
Какие из них ещё придётся настраивать?
Возьмем в пример следующие модели с huggingface и ollama: Mykes/medicus, gemma3, codegemma, codellama, dolphin-mistral, llava, falcon, mistral, llama2-uncensored, reefer/erplegend, gdisney/neural-chat-uncensored, reefer/erphermesl3, jimscard/adult-film-screenwriter-nsfw, Llama-2, Llama-3.2, nidum/Nidum-Llama-3.2-3B-Uncensored-GGUF, pygmalion (PygmalionAI).
Из них на Redmi 14C с PocketPal AI и ChatterUI лучше запускать модели с размером до 3-4 млрд параметров и с квантизацией 4-bit или 8-bit в формате GGUF/GGML.
Например:
- nidum/Nidum-Llama-3.2-3B-Uncensored-GGUF — 3B модель с GGUF.
- pygmalion (PygmalionAI) — часто доступна в облегчённых версиях.
- falcon, mistral — есть версии с квантизацией, но лучше выбирать меньшие варианты (7B и ниже).
- llama2-uncensored, Llama-2, Llama-3.2 — для Redmi 14C лучше использовать 3B или 7B версии с квантизацией.
- codellama, codegemma — кодовые модели, обычно тяжелее, но с квантизацией могут работать на 7B и ниже.
Интерфейсы и настройки, пояснения.
- PocketPal AI и ChatterUI — требуют минимальной настройки, если модель уже в GGUF с квантизацией. Для моделей без готовой квантизации придётся конвертировать и оптимизировать.
- LLM Farm — требует больше ручной настройки, особенно для мобильных устройств.
- Private LLM / Open LLM — часто требуют настройки под конкретное железо, оптимизации квантизации и формата.
1.2 Параметры.
Общие параметры для всех интерфейсов.
- Модель (Model path)
- Квантизация (Quantization)
- Размер контекста (Context size)
- Потоки CPU (Threads)
- Использование GPU (если поддерживается)
Укажите путь к модели в формате GGUF/GGML с квантизацией 4-bit или 8-bit, например: models/nidum-llama-3.2-3b.gguf
Это позволит загрузить оптимизированную модель, подходящую для ограниченных ресурсов Redmi 14C.
Укажите тип квантизации, например:--quantize 4bit или --quantize 8bit
Это уменьшит размер модели и нагрузку на CPU/GPU.
Например:--ctx_size 2048 или --ctx_size 4096
Чем больше контекст, тем больше памяти требуется. Для Redmi 14C лучше ограничиться 2048 токенами, чтобы избежать тормозов.
Например: --threads 4
Redmi 14C обычно имеет 4-8 ядер, но для стабильности лучше ограничить количество потоков до 4.
Если интерфейс поддерживает GPU-ускорение (например, через Vulkan или OpenCL), включите его: --use_gpu true
Но на Redmi 14C GPU слабый, поэтому часто лучше использовать CPU.
Специфичные параметры для PocketPal AI и ChatterUI
- Формат модели
- Оптимизация памяти
- Темп генерации (Temperature)
- Максимальная длина ответа (Max tokens)
Например:
PocketPal AI и ChatterUI лучше работают с GGUF/GGML. Убедитесь, что модель конвертирована в этот формат.
В PocketPal AI можно включить опцию: --low_vram true
Это уменьшит использование оперативной памяти.
Например: --temperature 0.7
Регулирует креативность ответов. Для более стабильных ответов ставьте 0.6-0.8.
Например: --max_tokens 256
Ограничивает длину генерируемого текста, чтобы не перегружать устройство.
Параметры для LLM Farm и Private/Open LLM
- Путь к модели и квантизация — как в общих параметрах
- Параметры запуска
- Настройка логирования
- Оптимизация под мобильные устройства
В LLM Farm часто нужно указывать дополнительные параметры запуска модели, например:
--use_mlock true — блокирует модель в памяти, чтобы избежать свопа (если хватает RAM).
--batch_size 8 — размер батча для генерации, уменьшайте для экономии ресурсов.
Для отладки полезно включить подробный лог: --verbose true
В некоторых случаях нужно вручную конвертировать модель с помощью инструментов типа llama.cpp с параметрами:
./quantize model.bin model.gguf 4 — для 4-битной квантизации.
Пояснения к параметрам
- --quantize Снижает размер модели и нагрузку на устройство.
- --ctx_size Размер окна контекста, влияет на память и качество.
- --threads Количество CPU потоков для обработки.
- --use_gpu Включение GPU-ускорения (если поддерживается).
- --low_vram Оптимизация использования памяти для слабых устройств.
- --temperature Контролирует креативность и разнообразие ответов.
- --max_tokens Максимальная длина генерируемого текста.
- --use_mlockБлокирует модель в RAM, чтобы избежать свопа.
- --batch_size Размер батча для генерации, влияет на скорость и память.
- --verbose Включает подробный лог для отладки.
1.3 Модели.
Модели с huggingface и ollama:
- Mykes/medicus
- gemma3
- codegemma
- codellama
- dolphin-mistral
- llava
- falcon
- mistral
- llama2-uncensored
- reefer/erplegend
- gdisney/neural-chat-uncensored
- reefer/erphermesl3
- jimscard/adult-film-screenwriter-nsfw
- Llama-2
- Llama-3.2
- nidum/Nidum-Llama-3.2-3B-Uncensored-GGUF
- pygmalion (PygmalionAI)
1.4 Итоги.
Для Xiaomi Redmi 14C при настройке интерфейсов LLM стоит ориентироваться на:
- Использование моделей с квантизацией 4-bit или 8-bit в формате GGUF/GGML.
- Ограничение контекста до 2048 токенов.
- Установка количества потоков CPU в 4.
- Включение оптимизаций памяти (--low_vram).
- Контроль температуры и максимальной длины ответа для баланса качества и производительности.
3. Ollama VPS/VDS
3.1. Ollama
Для работы ollama на виртуальном севере нужны следующие минимальные технические требования.
- VPS с Ubuntu 20.04+, а лучше Debian 12+
- 16 ГБ ОЗУ (минимум 8 ГБ)
- 50 ГБ SSD (для моделей)
- 4+ vCPU
- Доменное имя
Учтите 2 больших нюанса.
- Вам в любом случае придётся либо подобрать некую модель нейронной сети для работы, либо квантизировать её до нужного размера. Модель, которая будет по вашему мнению работать наилучшим образом для ваших задач. И проверить придётся немало моделей. Например, чтобы найти русскоязычную. Иначе будет только английский язык. Я знаю только о Gemini 2.5 Pro, другие еще не проверял, но и она слишком большая для ОЗУ в 16 ГБ.
- Любая модель на таких системных требованиях будет работать достаточно медленно и с этим придётся смириться, если не хотите платить заоблачные суммы либо за доступ к онлайн чатам, либо за сам сервер с уже серьезными боевыми характеристиками.
Предполагается, что вы уже знакомы с Linux-системами и умеете хотя бы базово настраивать сервер на базе ОС хотя бы Debian/Ubuntu, включая безопасность.
Если же нет - перейдите по этой ссылке и настройте. Не обязательно настраивать прямо всё-всё. Настройте только то, что вам необходимо, включая фаервол как обязательный параметр безопасности доступа к вашему серверу.
Что нужно установить?
- Docker & Docker Compose
- Ollama (локальные AI-модели)
- Open WebUI (веб-интерфейс)
- Nginx (обратный прокси)
- SSL сертификат
Подключаемся к серверу и устанавливаем необходимые компоненты.
Обновление системы.
sudo apt update && sudo apt upgrade -y
Docker и Docker-Compose можно установить по следующей инструкции.
Установка Ollama.
curl -fsSL https://ollama.com/install.sh | sh
Настройка доступа для Docker.
sudo systemctl stop ollama sudo mkdir -p /etc/systemd/system/ollama.service.d/ echo -e '[Service]\nEnvironment="OLLAMA_HOST=0.0.0.0"' | sudo tee /etc/systemd/system/ollama.service.d/environment.conf sudo systemctl daemon-reload sudo systemctl start ollama
Загрузка моделей (выберите нужные).
ollama pull llama3.1:8b ollama pull codellama:7b
Проверка установленных моделей.
ollama list
Создаем и запускаем Open WebUI контейнер.
Создание директории проекта.
mkdir ~/open-webui && cd ~/open-webui
Вариант-1, файл «docker.compose.yml».
nano docker.compose.yml version: '3.8' services: openwebui: image: ghcr.io/open-webui/open-webui:main ports: - "3000:8080" volumes: - ./data:/app/backend/data environment: - OLLAMA_BASE_URL=http://ollama:11434 depends_on: - ollama networks: - webui ollama: image: ollama/ollama volumes: - ollama_data:/root/.ollama ports: - "11434:11434" networks: - webui volumes: ollama_data: networks: webui: driver: bridge
Вариант-2, файл «docker.compose.yml».
nano docker.compose.yml
version: '3.8'
services:
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
restart: unless-stopped
ports:
- "8080:8080"
environment:
- OLLAMA_BASE_URL=http://localhost:11434
- WEBUI_SECRET_KEY=ваш_секретный_ключ
- WEBUI_AUTH=True
volumes:
- open-webui-data:/app/backend/data
network_mode: "host"
volumes:
open-webui-data:
Запуск контейнера.
docker compose up -d
Настраиваем доменный доступ через обратный прокси.
становка Nginx.
sudo apt install nginx -y
Создание конфигурации.
sudo nano /etc/nginx/sites-available/openwebui
server {
listen 80;
server_name ваш-домен;
location / {
proxy_pass http://localhost:8080;
proxy_set_header Host \$host;
proxy_set_header X-Real-IP \$remote_addr;
proxy_set_header X-Forwarded-For \$proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto \$scheme;
# WebSocket поддержка
proxy_http_version 1.1;
proxy_set_header Upgrade \$http_upgrade;
proxy_set_header Connection "upgrade";
proxy_read_timeout 86400;
}
client_max_body_size 100M;
}
Активация конфигурации.
sudo ln -s /etc/nginx/sites-available/openwebui /etc/nginx/sites-enabled/ sudo nginx -t sudo systemctl reload nginx
Настройка брандмауэра. Если вы используете UFW.
sudo ufw allow 80 sudo ufw allow 443 sudo ufw allow 22
Настройка брандмауэра. Если у вас более продвинутый фаервол Firewalld.
sudo firewall-cmd --permanent --add-port=80/tcp sudo firewall-cmd --permanent --add-port=443/tcp sudo firewall-cmd --permanent --add-port=22/tcp sudo firewall-cmd --reload
Добавляем HTTPS для безопасного соединения.
Установка Certbot.
sudo apt install certbot python3-certbot-nginx -y
Получение SSL сертификата.
sudo certbot --nginx -d ваш-домен
Автоматическое обновление.
sudo systemctl enable certbot.timer
Open WebUI предоставляет REST API для интеграции с другими приложениями.
Получение API ключа.
Settings → API Keys → Generate New Key
Решение частых проблем.
Open WebUI не видит модели Ollama.
Проверьте подключение между контейнерами.
curl http://localhost:11434/api/tags
Проверка из контейнера Open WebUI.
docker exec open-webui curl http://localhost:11434/api/tags
Перезапуск сервисов.
docker compose down docker compose up -d
Ошибки памяти при работе с большими моделями.
Для 12 ГБ ОЗУ рекомендуемые настройки:
- Max Tokens: 8192
- Модель: llama3.1:8b или codellama:7b
- Температура: 0.3
- Мониторинг памяти: запустите терминал и введите одну из команд, либо запустите несколько терминалов и позапускайте каждую команду.
- htop
- free -h
- docker stats
3.2. Подключение поисковых утилит на open-webui
Я считаю, что наиболее эффективными могут быть 2 вида поиска - это SearXNG и Google. С остальными пока не все ясно. Потому что например на сайте searchapi в личном кабинет указано, что: Remaining free searches (credits) 98.
Причем это после 2 моих попыток. Вроде бы пишут что там сколько-то поисков в день. А по факту на самом деле оказывается 100 поисков это всего бесплатно, а дальше платите и ничего сбрасываться не будет.
SearXNG поиск в docker.
Поэтому первый поиск, который вы можете настроить - это поисковая система SearXNG, установив её в docker как самую эффективную, потому что она является продолжением проекта SearX.
Для настройки перейдите на сайт настройки SearXNG для open-webui и следуйте всем инструкциям.
Да, они полностью на английском, но вроде как понятные, потому что инструкция для linux систем, кто хоть базово знаком.
Google programmable search engine.
Для настройки перейдите на этот сайт.
Вам нужно проделать следующие настройки.
В результате вы получите идентификатор поисковой системы. Он понадобится вам далее, скопируйте его.
После этого сделайте еще одну настройку, чтобы получить некий API ключ.
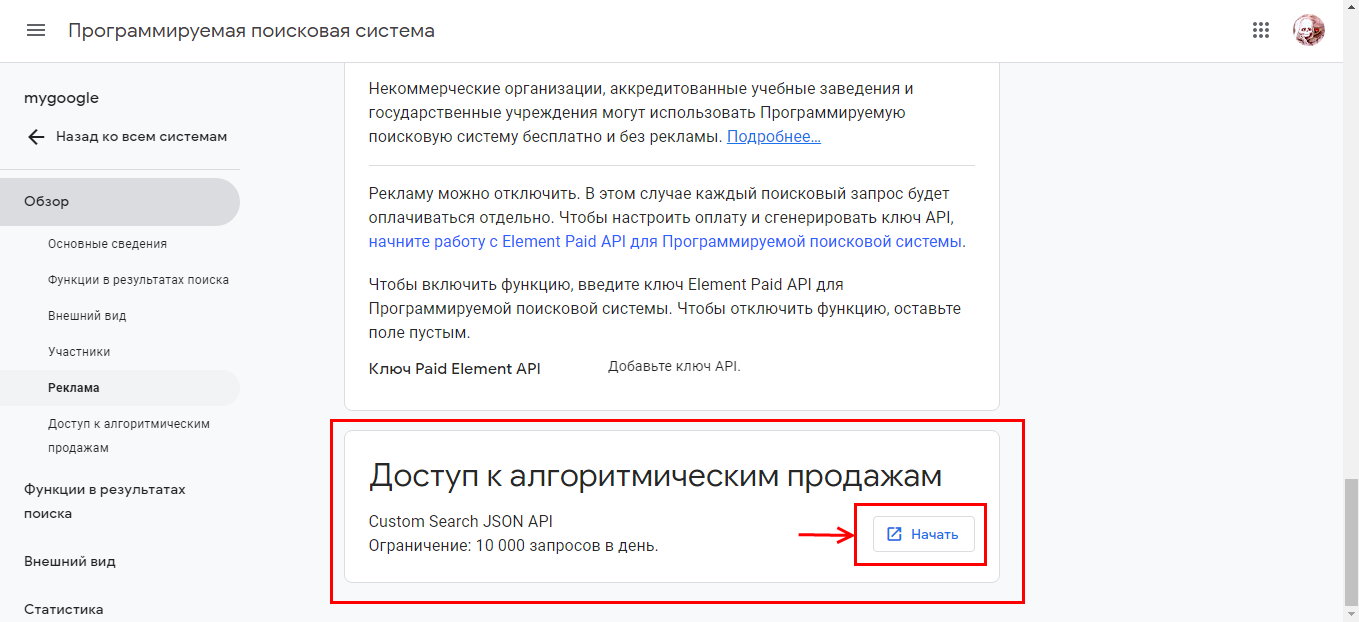
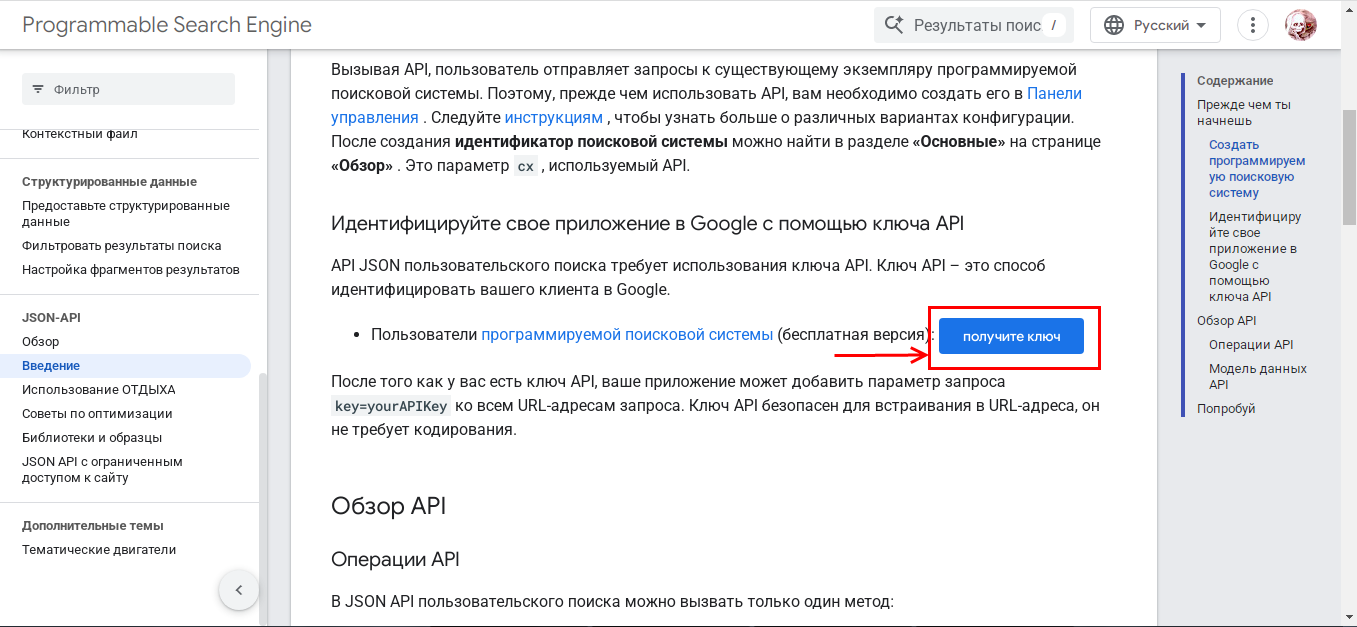
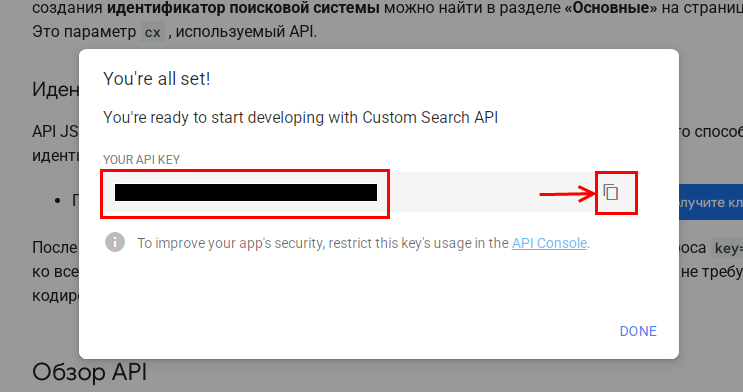
Теперь и идентификатор и API ключ необходимо вставить в настройки open-webui в соответствующие поля.
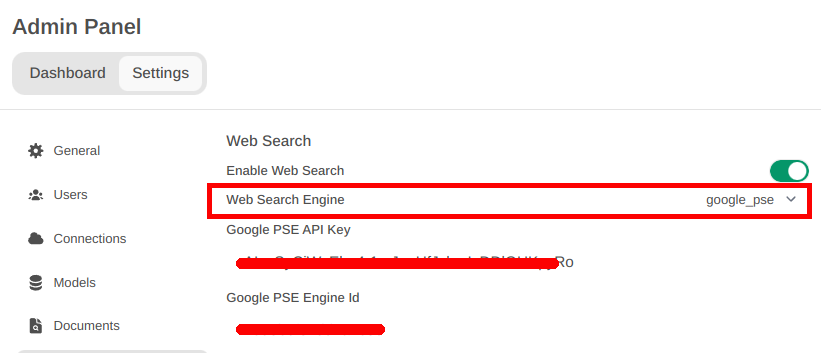
4. VPS/VDS n8nio/n8n
n8n — это инструмент для автоматизации рабочих процессов (workflow automation), который позволяет:
- Интегрировать множество разных сервисов и форматов данных.
- Автоматизировать сложные цепочки обработки данных, включая преобразование и маршрутизацию файлов разных форматов.
- Легко создавать пайплайны, где локальные нейросети могут взаимодействовать с внешними API, базами данных, системами хранения и генерацией изображений.
- Расширять функциональность за счёт множества готовых коннекторов и кастомных скриптов.
Нужно ли вам n8n?
- Если Open-WebUI с Ollama уже покрывает ваши основные задачи — поиск, обработку текстов и работу с локальными файлами — и вы не планируете сложных автоматизаций, то n8n может быть избыточен.
- Если же вы хотите обрабатывать разнообразные форматы файлов (например, PDF, DOCX, изображения), автоматически запускать генерацию изображений, связывать разные сервисы и создавать сложные сценарии обработки данных, то n8n значительно расширит ваши возможности.
- n8n особенно полезен, если вы хотите, чтобы локальные модели и сервисы работали в едином автоматизированном конвейере, где можно гибко управлять потоками данных и интеграциями.
Для настройки нужно создать отдельную директорию и создать конфигурационные файлы.
mkdir n8n && cd n8n && nano docker-compose.yml
version: '3.7'
services:
n8n:
image: n8nio/n8n
restart: always
ports:
- "127.0.0.1:5678:5678"
environment:
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=postgres
- DB_POSTGRESDB_PORT=5432
- DB_POSTGRESDB_DATABASE=${POSTGRES_DB}
- DB_POSTGRESDB_USER=${POSTGRES_USER}
- DB_POSTGRESDB_PASSWORD=${POSTGRES_PASSWORD}
- N8N_BASIC_AUTH_ACTIVE=true
- N8N_BASIC_AUTH_USER=${N8N_USER}
- N8N_BASIC_AUTH_PASSWORD=${N8N_PASSWORD}
- GENERIC_TIMEZONE=${GENERIC_TIMEZONE}
- WEBHOOK_URL=https://n8n.vash-site.ru/
volumes:
- n8n_data:/home/node/.n8n
depends_on:
- postgres
postgres:
image: postgres:11
restart: always
environment:
- POSTGRES_DB=${POSTGRES_DB}
- POSTGRES_USER=${POSTGRES_USER}
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
volumes:
- postgres_data:/var/lib/postgresql/data
volumes:
n8n_data:
postgres_data:
Создаем и открываем файл .env
nano .env # Укажите ваш часовой пояс, например Europe/Moscow GENERIC_TIMEZONE=Europe/Moscow # Придумайте логин и пароль для входа в интерфейс n8n N8N_USER=admin N8N_PASSWORD=SUPER_SECRET_PASSWORD_1 # Данные для базы данных. Можно оставить как есть, но пароль лучше сменить. POSTGRES_DB=n8n POSTGRES_USER=n8nuser POSTGRES_PASSWORD=SUPER_SECRET_PASSWORD_2
Запускаем n8n.
sudo docker-compose up -d sudo docker-compose ps
Сейчас n8n работает, но доступен только внутри сервера. Чтобы открыть его по вашему домену (`https://n8n.vash-site.ru`) и защитить соединение (HTTPS), нужен "посредник" — Reverse Proxy. Самый простой способ его настроить — использовать Nginx Proxy Manager in docker.
После его установки создайте новый Proxy Host:
- Domain Names: например «n8n.vash-site.ru» (ваш домен)
- Scheme: «http»
- Forward Hostname / IP: «127.0.0.1»
- Forward Port: «5678»
- На вкладке SSL выберите «Request a new SSL certificate» и включите «Force SSL».
Готово! Теперь вы можете зайти на свой домен, ввести логин/пароль из «.env» файла и начать автоматизировать!
Вместо Nginx Proxy Manager - вы вполне можете установить простой Nginx и настроить простейший Reverse-Proxy, а затем получить HTTPS сертификат посредством Certboot.
Для подобной настройки посмотрите данную инструкцию или читайте об том в главе выше.
5. Docker и Self-Hosted AI
Docker — основа современной AI инфраструктуры.
Docker: https://www.docker.com/
Docker Compose: https://docs.docker.com/compose/
Linux:
sudo pacman -S docker или sudo apt install docker docker-compose
Windows:
Docker Desktop: https://www.docker.com/products/docker-desktop/
GPU support: install-guide - NVIDIA Container Toolkit.
Пример:
docker run --gpus all nvidia/cuda:12.4.0-base nvidia-smi
Почему Docker важен:
- изоляция
- portability
- reproducibility
- deployment
Open WebUI: https://github.com/open-webui/open-webui
Запуск:
docker run -d -p 3000:8080 ghcr.io/open-webui/open-webui:main
6. Linux Survival Guide
Главное правило: НЕ устанавливать AI пакеты в system Python.
Использовать:
- uv
- venv
- docker
Почему: pip install может сломать систему.
Arch Linux: особенно чувствителен.
Проблемы:
- broken CUDA
- broken ROCm
- broken torch
- libcudnn conflicts
Рекомендуется:
Timeshift: https://github.com/linuxmint/timeshift
Backup:
- drivers
- CUDA
- environments
Portable AI:
- отдельный SSD
- portable Python
- portable models
HuggingFace cache: ~/.cache/huggingface/
Полезно: делать symlink моделей.
7. AI агенты и automation
AI Agents:
это системы которые:
- используют инструменты
- браузер
- shell
- API
- память
- n8n: https://n8n.io/
- Flowise: https://flowiseai.com/
- LangGraph: https://www.langchain.com/langgraph
MCP: Model Context Protocol.
Используется для:
- IDE integration
- filesystem access
- browser tools
- external APIs
Почему агенты важны: LLM без инструментов ограничены.
С инструментами: они могут:
- искать файлы
- писать код
- открывать браузер
- автоматизировать задачи
8. Практические AI стеки
Weak PC:
- CPU only
- GGUF
- Q4_K_M
- llama.cpp
Mid-End:
- RTX 3060/4060
- EXL2
- TabbyAPI
- SillyTavern
High-End:
- RTX 4090/5090
- vLLM
- 70B models
- multi-user inference
Mac:
- MLX
- Metal
- LM Studio
Portable stack:
- external SSD
- Docker
- portable Python
- local models
Практика: самое важное: стабильность и удобство.
Ну а сегодня на этом всё. Всем Добра и Удачи!
Copyright © 26.10.2025 by Mikhail Artamonov