Hogwarts in Python
Волшебный Python или как не споткнуться о pathlib.
Оглавление
- Введение
- Структура «проекта-примера»
- Cодержимое файлов «проекта-примера»
- Импорт пакетов
- Сравнение «pathlib» с модулями «os» и «os.path»
- Библиотека «pathlib». Примеры использования на практике
- Введение в pathlib.
- Гайд по pathlib на реальных примерах.
- Базовое имя пути
- Расширение файла
- Абсолютный и относительные пути
- Соединение путей
- Права доступа
- Права доступа (chmod)
- Смена владельца и/или группы (os.chown)
- Смена владельца и/или группы (shutil.chown)
- Создание файлов и папок
- Переименование файлов и папок
- Перемещение файлов и папок
- Удаление файлов и папок
- Cписок файлов и директорий в папке
- Рекурсивные операции
- Вывод
- Задачи с решениями
- Немного «unittest»
- О Python в Windows 7, 10 и выше, а также WINE
1. Введение
1.1. Предисловие.
Для всех тестов и примеров для условий наиболее приближенных к реальным я буду использовать виртуальную машину с Debian 10, и 2 мя SHELL-ами: Fish (Default) и Bash и Python 3.10.
Fish используется только для удобства - у него прекрасное автозавершение команд, а также их цветная подсветка.
Пользователь также использован временный.
Виртуальное окружение для подобных тестов не требуется.
1.2. Введение.
При создании любого python-проекта или одиночного скрипта с кодом мы часто пользуемся импортом, не совсем понимая или не помня, как именно он работает. В связи с чем, иногда могут возникать казусы и непредвиденные ситуации, которые порой сложно решить даже с использованием «Google» поиска.
Сегодня моя задача объяснить почему возникают ошибки импорта пакетов или модулей, а также рассказать сложные темы простыми словами. Темы нашего сегодняшнего разговора очень простые, не смотря на то, что кажутся жутко сложными на первый взгляд. Однако, даже не углубляясь глубоко в дебри языка можно легко прийти к выводу - что любая задача решается очень легко.
Даже если мы не знаем какая библиотека сможет решить ту или иную задачу, мы всегда должны понимать что способов решений может быть много, а может быть ни одного. В любом случае каждый раз вам придётся не только искать то или иное решение, но и искать его самостоятельно. Порою вы сможете найти сразу готовое решение и оно вам подойдет. Однако, так будет не всегда.
В любом случае вам нужно опираться на несколько базовых понятий:
- Какой нужен результат ?
- Решается ли задача, хотя бы на бумаге ?
- Алгоритмизация решения.
Допустим, вы уже решили ту или иную объемную задачу на бумаге, создали не только алгоритм решения, но и создали собственный python-пакет для обработки подобных задач в будущем.
После этого вам наверняка понадобится протестировать свой пакет не только на ошибки, но и на избыточность кода, а также соблюдение отступов, синтаксиса и многого другого.
Вы конечно можете создать отдельный файл скрипта, например «test.py» в конкретной директории вашего пакета и протестировать модуль или метод модуля отдельно, так сказать, вручную. Однако, это мягко говоря неудобно!
Для каждого модуля вам придётся мучиться не только с отдельными скриптами-тестами, но с импортом своих модулей в этих скриптах. Мало того, эти файлы-тесты будут включены в ваш пакет и мешать вам отлаживать его работу.
Не говоря уже про попытку теста всего пакета в целом, ведь в этом случае - относительный импорт не работает и вам придется переместить ваш тест-скрипт на директорию выше, а может и вообще перед директорией вашего пакета. И так будет с каждым скриптом-тестом.


В результате вам всё-таки придётся создать отдельную директорию для тестирования своего кода, в которой вы и будете хранить все скрипты-тесты вашего кода.
Это как раз правильный подход! Однако, есть нюансы.
Вот тут то и начинается вся магия «Абры-Кадабры» с импортом, т.к. в этом случае относительный импорт - не работает!

Что же тогда делать и как решить такую задачу?
Всё решается буквально 1...2 строчками кода - но их необходимо понимать, чтобы применять правильно.
Но - обо всём по порядку!
2. Структура «проекта-примера»
Общая структура.
Для примера пусть будет следующая структура проекта.

.
└── pkg
├── compatible
│ ├── functions.py
│ ├── __init__.py
│ ├── subpackage_a
│ │ ├── a.py
│ │ └── __init__.py
│ ├── subpackage_b
│ │ ├── b.py
│ │ ├── __init__.py
│ │ └── test-pathlib-1.py
│ └── test.py
├── test.py
└── tests
├── __init__.py
├── test-abs-path.py
├── test-pathlib-1.py
├── test-pathlib-2.py
├── test-pkg-simple.py
├── test.py
└── tmp.txt
3. Cодержимое файлов «проекта-примера»
Определим содержимое всех указанных файлов-проекта. Для примера, пусть будет следующим.
3.1 Пакет: compatible
Файл: pkg/compatible/__init__.py
from .functions import * from .subpackage_a import * from .subpackage_b import *
Файл: pkg/compatible/functions.py
__all__ = ['getDateTimeStr'] from datetime import datetime def getDateTimeStr(strFormat = "%d.%m.%Y-%H:%M:%S") -> str: dateTime = datetime.now() outDateTime = dateTime.strftime(strFormat) return outDateTime
3.2. Под-пакет: subpackage_a
Файл пакета subpackage_a: pkg/compatible/subpackage_a/__init__.py
from .a import *
Файл пакета subpackage_a: pkg/compatible/subpackage_a/a.py
__all__ = ['getPackageA'] from ..functions import * def getPackageA(): return 'Package A:' + getDateTimeStr()
3.3. Под-пакет: subpackage_b
Файл пакета subpackage_b: pkg/compatible/subpackage_b/__init__.py
from .b import *
Файл пакета subpackage_b: pkg/compatible/subpackage_b/b.py
__all__ = ['getPackageB'] from ..functions import * def getPackageB(): return 'Package B:' + getDateTimeStr()
4. Импорт пакетов
4.1. Как работает импорт?
При относительном импорте в пакете мы обращаемся к заданному каталогу относительно текущего. Тогда почему при запуске скрипта мы всё равно не можем импортировать пакет или модуль пакета на уровень выше?
Это немного ошибочное мнение.
Дело в том, что модуль внутри пакета - по команде import или from обращается относительно себя. Между модулями или между пакетами такое относительное обращение вполне нормальное явление.
Например, находясь в одном из подкаталогов пакета compatible: from ..compatible.functions import getDateTimeStr
При простом запуске скрипта, т.е. исполняемого файла, по команде import или from Python ищет пакеты по заданному наименованию в каталогах, которые заданны в sys.path. Относительного импорта при запуске python-скрипта нет. Поэтому при попытке относительного импорта в запускаемом скрипте мы видим различные ошибки.
Т.е. в запускаемом файле при импорте необходимо указывать именно наименование модуля, в то время как внутри пакета в модулях при импорте необходимо соблюдать относительность путей.
Например: import pathlib, или from pathlib import Path.
Оказывается, просто, необходимо добавить директорию родителя в данную переменную среды.
Однако, остаётся ещё один вопрос: А какой именно каталог необходимо добавить: ../, ./ или абсолютный путь ?
Давайте узнаем всё это на практике.
Сначала добавим относительный путь и посмотрим - появился ли он в sys.path.
import sys sys.path.append('../')

Есть.
Теперь попробуем импортировать наш модуль.

Хм, ошибка. Может неправильно указали относительную директорию? Давайте попробуем с помощью модуля pathlib.

Опять ошибка. Может опять относительность импорта указали не верно? Попробуем ещё раз.

Хм, снова ошибка.
Однако, здесь не всё так просто, как показалось на первый взгляд.
Давайте разбираться!
4.2. Абсолютные и относительные пути.
Давайте сначала посмотрим как получить полную директорию из относительной при помощи того же модуля pathlib.

Хорошо. С директориями разобрались.
Есть такая встроенная переменная как «__file__». Она указавает на текущий скрипт.
Добавим новый путь поиска пакетов и попробуем импортировать наш пакет. Заодно посмотрим на пространстфо имен запускаемого скрипта, а также пространство имен импортируемого модуля. Если всё получится в консоль будут выведены все указанные значения.
import pathlib import sys sys.path.append(str(pathlib.Path(__file__).resolve().parent.parent)) def main(): for i in sys.path: print(i) import compatible print(dir(sys.modules[__name__])) print(dir(compatible), '\n') print(compatible.getPackageA()) print(compatible.getPackageB()) if __name__ == '__main__': main()
Смотрим на результат.

Ура! Заработало!
Однако, такой способ добавления не совсем правильный! Однако, вполне рабочий.
Обратите внимание на то, что необходимый путь поиска добавился в последнюю строку в «sys.path».
Таким образом, Python сначала переберет все остальные пути поиска, и только в последнюю очередь будет обращаться к вашей заданной директории.
Лучшим решением, будет - добавление вашей директории на первое место. С этим как раз и поможет метод insert.
import pathlib import sys sys.path.insert(0, str(pathlib.Path(__file__).resolve().parent.parent)) def main(): for i in sys.path: print(i) import compatible print(dir(sys.modules[__name__])) print(dir(compatible), '\n') print(compatible.getPackageA()) print(compatible.getPackageB()) if __name__ == '__main__': main()

5. Сравнение «pathlib» с модулями «os» и «os.path»
Не все пары функций/методов ниже эквивалентны. Некоторые из них частично совпадают, некоторые имеют разную семантику. К ним относятся os.path.abspath() и Path.resolve(), os.path.relpath() и Path.relative_to().
Функция os.path.abspath() не разрешает символические ссылки, в то время как Path.resolve() это делает.
Метод Path.relative_to() требует, чтобы путь pathlib.Path был подпутем аргумента, однако, os.path.relpath() этого не требует.
Подробные примеры использования разберем в следующей главе.
| Функции модулей os и os.path | Функции модуля pathlib |
|---|---|
| os.path.abspath() | Path.resolve() |
| os.chmod() | Path.chmod() |
| os.mkdir() | Path.mkdir() |
| os.makedirs() | Path.mkdir() |
| os.rename() | Path.rename() |
| os.replace() | Path.replace() |
| os.rmdir() | Path.rmdir() |
| os.remove(), os.unlink() | Path.unlink() |
| os.getcwd() | Path.cwd() |
| os.path.exists() | Path.exists() |
| os.path.expanduser() | Path.expanduser() и Path.home() |
| os.listdir() | Path.iterdir() |
| os.path.isdir() | Path.is_dir() |
| os.path.isfile() | Path.is_file() |
| os.path.islink() | Path.is_symlink() |
| os.link() | Path.hardlink_to() |
| os.symlink() | Path.symlink_to() |
| os.readlink() | Path.readlink() |
| os.path.relpath() | Path.relative_to() |
| os.stat() | Path.stat(), Path.owner(), Path.group() |
| os.path.isabs() | PurePath.is_absolute() |
| os.path.join() | PurePath.joinpath() |
| os.path.basename() | PurePath.name |
| os.path.dirname() | PurePath.parent |
| os.path.samefile() | Path.samefile() |
| os.path.splitext() | PurePath.suffix |
6. Библиотека «pathlib». Примеры использования на практике
6.1. Введение в pathlib.
Каждая операционная система имеет разные правила построения путей к файлам. Например, Linux использует прямые косые черты для путей, в то время как Windows использует обратную косую черту.
Это небольшое различие может вызвать проблемы, если вы работаете над проектом и хотите, чтобы другие разработчики из разных операционных систем расширили ваш код.
К счастью, если вы пишете на Python, модуль Pathlib выполняет тяжелую работу, позволяя вам убедиться, что ваши пути к файлам работают одинаково в разных операционных системах. Кроме того, он предоставляет функциональные возможности и операции, которые помогут вам сэкономить время при обработке и манипулировании путями.
Откройте файл, например main.py и введите следующее содержимое:
import pathlib
p = pathlib.Path(__file__)
print(type(p), ':', p)
Сохраните и запустите. У меня вывод получился следующий:
mikl ~/003/Primer $ python main.py
‹class 'pathlib.PosixPath'› : /home/mikl/003/Primer/main.py
Как показано выше, Pathlib создает путь к этому файлу, помещая этот конкретный скрипт в объект Path. Pathlib разделяет пути файловой системы на два разных класса, которые представляют два типа объектов path: чистый путь и конкретный путь.
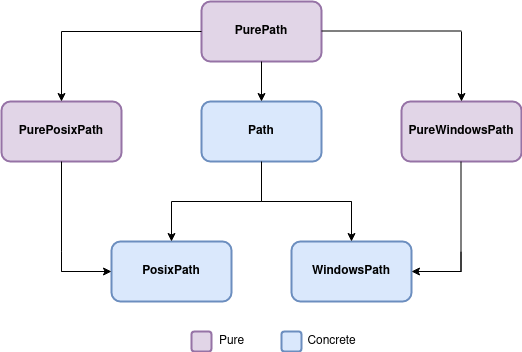
Чистый путь предоставляет утилиты для обработки и управления вашим путем к файлу без выполнения операций записи, в то время как конкретный путь позволяет вам манипулировать и выполнять операции записи в вашем пути к файлу.
Другими словами, конкретный путь является подклассом чистого пути. Он наследует манипуляции от родительского класса и добавляет операции ввода / вывода, которые выполняют системные вызовы.
Чистые пути манипулируют путем к файлу на вашем компьютере, даже если он принадлежит другой операционной системе. Например, допустим, вы работаете в Linux и хотите использовать путь к файлу Windows. Здесь объекты класса PurePath помогут вам заставить путь работать на вашем компьютере с некоторыми базовыми операциями, такими как создание дочерних путей или доступ к отдельным частям пути.
Но чистые пути не смогут имитировать некоторые другие операции, такие как создание каталога или файла, потому что вы на самом деле не в этой операционной системе.
Модифицируем код представленный выше и одной командой получим на выходе прежний str:
import pathlib
p = str(pathlib.Path(__file__))
print(type(p), ':', p)
Сохраните и запустите:
mikl ~/003/Primer $ python main.py
‹class 'str'› : /home/mikl/003/Primer/main.py
Как видите преобразовать объекты типа Path в строку не так уж и сложно.
6.2. Гайд по pathlib на реальных примерах.
А теперь давайте сравним «pathlib» с «os» и «os.path» на практике на наиболее часто используемых методах.
6.2.1. Базовое имя пути
6.2.1.1. Имя файла
Добавим в вывод дополнительную информацию, чтобы понимать какой объект мы получаем и выводем содержимое на экран.
$ nano main.py
import os
names = os.path.basename(__file__)
print(type(names), ':', names)
$ python main.py
‹class 'str'› : main.py
А теперь тоже самое в pathlib.
$ nano main.py
import pathlib
filename = pathlib.Path('/path/to/somefile.txt').name
print(type(filename), ':', filename)
$ python main.py
‹class 'str'› : somefile.txt
Пока неясно какой модуль лучше. Результат у обоих абсолютно одинкавый.
У библиотеки os не так много методов для работы с путями. Однако, pathlib предоставляет гораздо более широкий спектр возможностей. Рассмотрим несколько других свойств, которые могут помочь в той или иной ситуации.
6.2.1.2. Базовые директории
Как получить пути к основным директориям системы? Например, к текущей, из которой запущен скрипт и к домашнему каталогу.
Рассмотрим пример 3 библиотек: os, os.path и pathlib.
mikl ~/003/Primer $ nano main.py
import os
import os.path
import pathlib
print('pathlib:')
print(pathlib.Path.cwd())
print(pathlib.Path.home())
print(pathlib.Path('~/Downloads').expanduser())
print('os and os.path:')
print(os.getcwd())
print(os.path.expanduser("~"))
mikl ~/003/Primer $ python main.py
pathlib:
/home/mikl/003/Primer
/home/mikl
/home/mikl/Downloads
os and os.path:
/home/mikl/003/Primer
/home/mikl
На самом деле следующие методы чатично работают и в Linux.
PurePath.parts - возвращает кортеж, последовательность сегментов пути, проанализированных на основе значения разделителя пути.
PurePath.drive - возвращает строку, представляющую букву или имя диска, если она есть.
PurePath.root - возвращает строку, представляющую локальный или глобальный корень, если он есть.
PurePath.anchor - возвращает строку, представляющую конкатенацию диска и корня.
PurePath.parent - возвращает строку, представляющую логический родительский путь.
PurePath.name - возвращает строку, представляющую конечный компонент пути, исключая диск и корень, если он есть. Другими словами это имя файла или название последней директории в пути.
PurePath.suffix - возвращает строку, представляющую расширение файла, если он есть.
PurePath.suffixes - возвращает список, представляющий расширения файла, если он есть.
PurePath.stem - возвращает строку, представляющую последний компонент пути без суффикса.
PurePath.as_posix() - возвращает строковое представление пути с косыми чертами '/'.
PurePath.as_uri() - возвращает строку, представляющую путь как file URI. если путь не абсолютен, то поднимается исключение ValueError.
Пример использования.
mikl ~/003/Primer $ tar -cvzf ./strukture.txt.tar.gz ./strukture.txt
mikl ~/003/Primer $ nano main.py
import pathlib
p = pathlib.Path('./strukture.txt.tar.gz').resolve()
print(p.parts)
print(p.drive)
print(p.root)
print(p.anchor)
print(p.parent)
print(p.name)
print(p.suffix)
print(p.suffixes)
print(p.stem)
print(p.as_posix())
print(p.as_uri())
mikl ~/003/Primer $ wine-cmd
Z:\home\mikl\003\Primer> cmd.bat
Z:\home\mikl\003\Primer> python main.py
('Z:\\', 'home', 'mikl', '003', 'Primer', 'strukture.txt.tar.gz')
Z:
\
Z:\
Z:\home\mikl\003\Primer
strukture.txt.tar.gz
.gz
['.txt', '.tar', '.gz']
strukture.txt.tar
Z:/home/mikl/003/Primer/strukture.txt.tar.gz
file:///Z:/home/mikl/003/Primer/strukture.txt.tar.gz
А вот так выполнение этого же кода выглядит в Linux.
mikl ~/003/Primer $ python main.py
('/', 'home', 'mikl', '003', 'Primer', 'strukture.txt.tar.gz')
/
/
/home/mikl/003/Primer
strukture.txt.tar.gz
.gz
['.txt', '.tar', '.gz']
strukture.txt.tar
/home/mikl/003/Primer/strukture.txt.tar.gz
file:///home/mikl/003/Primer/strukture.txt.tar.gz
Непонятные для вас команды уточняйте в пункте-9 данной статьи.
Стоит отдельно выделить метод Path.samefile(other_path).
Этот метод вернет True, если путь path указывает на тот же файл, что и аргумент other_path, который может быть либо объектом pathlib.Path, либо строкой.
Семантика похожа на функции os.path.samefile() и os.path.samestat().
Вот так выглядит использование этого метода.
mikl ~/003/Primer $ nano main.py
from pathlib import Path
p = Path('cmd.bat')
q = Path('strukture.txt')
print(p.samefile(q))
print(p.samefile('cmd.bat'))
mikl ~/003/Primer $ python main.py
False
True
6.2.2. Расширение файла
Получаем расширение файла.
$ nano main.py
import os
import pathlib
# os.path
filename, file_extension = os.path.splitext('/path/to/somefile.txt')
print(type(file_extension), ':', file_extension)
# pathlib
file_extension = pathlib.Path('/path/to/somefile.txt').suffix
print(type(file_extension), ':', file_extension)
$ python main.py
‹class 'str'› : .txt
‹class 'str'› : .txt
6.2.3. Абсолютный и относительные пути
А теперь рассмотрим следующие методы библиотек: полный путь, получение родительской директории и соединение путей.
Полный путь, т.е. абсолютный путь.
mikl ~/003/Primer $ nano main.py
import os
import pathlib
# os.path
realdir = os.path.abspath(__file__)
print(type(realdir), realdir)
# pathlib.Path
pathdir = pathlib.Path(__file__).resolve()
print(type(pathdir), pathdir)
mikl ~/003/Primer $ python main.py
‹class 'str'› /home/mikl/003/Primer/main.py
‹class 'pathlib.PosixPath'› /home/mikl/003/Primer/main.py
Получение родительской директории, например, на 2 уровня вверх. Т.е. наименование директории, в которой находится файл, а также получить директорию на уровень вверх.
mikl ~/003/Primer $ nano main.py
import os
import pathlib
# os.path
two_up = os.path.dirname(os.path.dirname(__file__))
print(two_up)
# pathlib.Path
two_up = pathlib.Path(__file__).parent.parent
print(two_up)
mikl ~/003/Primer $ python main.py
/home/mikl/003
/home/mikl/003
В os.path без вложенных вызовов самой библиотеки не бойтись. А вот в pathlib.Path такой последовательный вызов команд вполне нормальное явление.
Согласитесь - с pathlib код становится красивым, менее громоздким и более читабельным.
Канонический путь в os.path
mikl ~/003/Primer $ nano main.py
import os
import pathlib
# os.path
src = './pkg/test.py'
dst = './test.py'
# При наличии имеющейся символической ссылки на файл, необходимо её удалить
# Чтобы создание символической ссылки не вызывало исключение FileExistsError
os.remove(dst)
os.symlink(src, dst)
print('os.symlink:', os.readlink(dst))
link = os.path.realpath(dst)
print('os.path.realpath:', link)
mikl ~/003/Primer $ python main.py
os.symlink: ./pkg/test.py
os.path.realpath: /home/mikl/003/Primer/pkg/test.py
Вычисление относительных путей в pathlib
mikl ~/003/Primer $ nano main.py
import pathlib
shark = pathlib.Path("ocean", "animals", "fish", "shark.txt")
below_ocean = shark.relative_to(pathlib.Path("ocean"))
below_animals = shark.relative_to(pathlib.Path("ocean", "animals"))
print(shark)
print(below_ocean)
print(below_animals)
mikl ~/003/Primer $ python main.py
ocean/animals/fish/shark.txt
animals/fish/shark.txt
fish/shark.txt
Метод relative_to возвращает новый объект Path, относящийся к данному аргументу.
Если relative_to не сможет вычислить ответ, он выдаст ValueError.
mikl ~/003/Primer $ nano main.py
import pathlib
shark = pathlib.Path("ocean", "animals", "fish", "shark.txt")
shark.relative_to(pathlib.Path("unrelated", "path"))
mikl ~/003/Primer $ python main.py
Traceback (most recent call last):
File "/home/mikl/003/Primer/main.py", line 4, in ‹module›
shark.relative_to(pathlib.Path("unrelated", "path"))
File "/usr/lib/python3.10/pathlib.py", line 816, in relative_to
raise ValueError("{!r} is not in the subpath of {!r}"
ValueError: 'ocean/animals/fish/shark.txt' is not in the subpath of 'unrelated/path' OR one path is relative and the other is absolute.
.relative_to()")
6.2.4. Соединение путей
mikl ~/003/Primer $ nano main.py
import os
import pathlib
# os.path
one = os.path.join('home', 'User', 'Desktop', 'file.txt')
print('os.path', one)
# os.path для абсолютного пути
asb_one = os.path.abspath(one)
print('os.path', asb_one)
# pathlib.Path
# Можно так
two = pathlib.Path('home', 'User', 'Desktop', 'file.txt')
print('pathlib', two)
# Можно и так
troyka = pathlib.Path('home').joinpath('User').joinpath('Desktop').joinpath('file.txt')
print('pathlib', troyka)
# В pathlib для абсолюнтого пути не требуются вложенные вызовы
four = troyka.resolve()
print('pathlib', four)
mikl ~/003/Primer $ python main.py
os.path home/User/Desktop/file.txt
os.path /home/mikl/003/Primer/home/User/Desktop/file.txt
pathlib home/User/Desktop/file.txt
pathlib home/User/Desktop/file.txt
pathlib /home/mikl/003/Primer/home/User/Desktop/file.txt


6.2.5. Права доступа
6.2.5.1. Права доступа (chmod)
Представьте себе ситуацию, в которой вам срочно понадобилось програмно создать папку, дать её определённые права доступа, а по окончании работы удалить её. Такое может понадобится при создании некой программы с уникальным шифрованием, или программы с шифрованием GPG для неких целей защиты того или иного доступа. Например, пакет python-gnupg поддерживает такой функционал.
Прежде, чем мы рассмотрим как раздавать права доступа, давайте посмотрим как их получить, а также как вывести на экран.
Для преобразования в нормальный и понятный для нас вид воспользуемся библиотекой stat, а именно, методами filemode и S_IMODE.
Где восьмеричное число - это:
- 0 - никаких прав
- 1 - только выполнение
- 2 - только запись
- 3 - выполнение и запись
- 4 - только чтение
- 5 - чтение и выполнение
- 6 - чтение и запись
- 7 - чтение запись и выполнение
Права доступа складываются из 3 категорий:
- u - владелец файла
- g - группа файла
- o - все остальные пользователи
Например.
- u+x - разрешить выполнение для владельца
- ugo+x - разрешить выполнение для всех
- ug+w - разрешить запись для владельца и группы
- o-x - запретить выполнение для остальных пользователей
- ugo+rwx - разрешить всё для всех
- 777 - Аналогично, разрешить всё для всех
- 755 - разрешить владельцу всё, а группе и остальным пользователям только читать и выполнять
Я заранее создал каталог gpgtest и дал ему права 700 вручную, т.е. полный доступ только владельцу каталога. Дело в том, что утилита GNUPG требует для рабочей директории именно такие права доступа.

Посмотрим как получить права доступа при помощи библиотек os и pathlib.
mikl@mikl ~/0/Primer> nano main.py
import os
import pathlib
from stat import S_IMODE, filemode
# Pathlib.Path.stat
p = pathlib.Path('./gpgtest')
print(p.stat().st_mode, filemode(p.stat().st_mode), oct(S_IMODE(p.stat().st_mode)))
# os.stat
statinfo = os.stat('./gpgtest')
print(statinfo.st_mode, filemode(statinfo.st_mode), oct(S_IMODE(statinfo.st_mode)))
mikl@mikl ~/0/Primer> python main.py
16832 drwx------ 0o700
16832 drwx------ 0o700
Всё работает!
Оставим только pathlib.Path.stat, и oct вывод прав доступа для одного из следующих примеров.
У нас имеется строка в виде последовательно записанных нуля и английской буквы 'o'. Попробуем преобразовать заданные из ввода права доступа в правильный формат и обратно.
Введём, например 755 и посмотрим что получится.
mikl@mikl ~/0/Primer> nano main.py
mode = '0o' + str(int(input('Введите права доступа: ')))
real_mode = int(mode, 8)
print(mode, real_mode, oct(real_mode))
mikl@mikl ~/0/Primer> python main.py
Введите права доступа: 755
0o755 493 0o755
Работает. Попробуем изменить права доступа к каталогу gpgtest и файлу strukture.txt разными библиотеками и посмотрим чем они отличаются.
pathlib.Path.chmod. Поменяем права с 700 на 755.
mikl@mikl ~/0/Primer> nano main.py
import pathlib
from stat import S_IMODE
p = pathlib.Path('./gpgtest')
print(oct(S_IMODE(p.stat().st_mode)))
mode = '0o755'
real_mode = int(mode, 8)
pathlib.Path(p).chmod(real_mode)
print(oct(S_IMODE(p.stat().st_mode)))
mikl@mikl ~/0/Primer> python main.py
0o700
0o755
У pathlib есть ещё один метод - Path.lchmod(mode).
Path.lchmod() не следует символическим ссылкам. Т.е. если путь Path указывает на символическую ссылку, изменяется режим chmod символической ссылки, а не целевого объекта, на который она указывает.
os.chmod. Поменяем права обратно на 700.
mikl@mikl ~/0/Primer> nano main.py
import os
from stat import S_IMODE
my_dir = './gpgtest'
statinfo = os.stat(my_dir)
print(oct(S_IMODE(statinfo.st_mode)))
mode = '0o700'
real_mode = int(mode, 8)
os.chmod(my_dir, real_mode)
statinfo = os.stat(my_dir)
print(oct(S_IMODE(statinfo.st_mode)))
mikl@mikl ~/0/Primer> python main.py
0o755
0o700
Обратите внимание на подчеркнутую строку. Для получения статуса в OS необходимо повторно запрашивать права доступа к файлу или папке. В pathlib запрос прав доступа происходит автоматически во время обращения к команде статуса файла или папки.
Можно немного уменьшить количество кода вложенными запросами.
import os
from stat import S_IMODE
my_dir = './gpgtest'
print(oct(S_IMODE(os.stat(my_dir).st_mode)))
mode = '0o700'
real_mode = int(mode, 8)
os.chmod(my_dir, real_mode)
print(oct(S_IMODE(os.stat(my_dir).st_mode)))
Однако, помните, что для библиотеки OS запрашивать права доступа, т.е. обращаться к статусу состояния файла или папки необходимо повторно.

6.2.5.2. Смена владельца и/или группы (os.chown)
У pathlib нет методов chown. Поэтому здесь всё-таки придётся использовать библиотеку os.
Вообще у os есть два метода: os.chown() и os.lchown().
Синтаксис у них следующий:
- os.chown(path, uid, gid, *, dir_fd=None, follow_symlinks=True)
- os.lchown(path, uid, gid)
Параметры означают следующее:
- path - str путь в файловой системе.
- uid - числовой идентификатор пользователя
- gid - числовой идентификатор группы
- dir_fd - дескрипторов каталога
- follow_symlinks - bool, переходить ли по ссылкам.
Данный метод не возвращает никаких значений!
Чтобы оставить один из идентификаторов без изменений, установите его на -1.
Функция os.lchown() эквивалентна вызову функции os.chown() с установленным аргументом follow_symlinks=False, например, os.chown(path, uid, gid, follow_symlinks=False).
Аргумент path в обоих функциях можно вставить как pathlib.PurePath.
Пример использования.
mikl ~/003/Primer $ nano main.py
import os
f = 'strukture.txt'
os.stat(f).st_gid
# 1000
os.stat(f).st_uid
# 1000
os.chown(f, -1, 1001)
os.stat(f).st_gid
# 1001
os.stat(f).st_uid
mikl ~/003/Primer $ sudo python main.py
[sudo] пароль для mikl:
985
1000
1001
1000
mikl ~/003/Primer $ ls -lha
итого 32K
drwxr-xr-x 3 mikl users 4,0K июл 24 09:12 .
drwxr-xr-x 3 mikl users 16K июл 22 17:35 ..
-rw-r--r-- 1 mikl users 234 июл 24 09:12 main.py
drwxr-xr-x 4 mikl users 4,0K июл 22 00:04 pkg
-rwxr-xr-x 1 mikl 1001 73 июл 24 00:28 strukture.txt
6.2.5.3. Смена владельца и/или группы (shutil.chown)
На самом деле это не столько правильный, сколько более понятный метод.
Синтаксис у него следующий:
- shutil.chown(path, user=None, group=None)
Где параметры:
- path - путь к файлу/каталогу
- user - пользователь
- group - группа
Этот метод тоже не возвращает никаких значений.
Функция chown() модуля shutil меняет владельца пользователя и/или группы по указанному пути.
Рассмотрим пример.
mikl@mikl ~/0/Primer> nano main.py import os import shutil, pathlib import pwd username = os.getlogin() on_uid = pwd.getpwnam(username).pw_uid print(f"username: {username}, uid: {on_uid}") my_dir = 'test_dir' on_dir = pathlib.Path(my_dir) if not on_dir.exists(): on_dir.mkdir(parents=True, exist_ok=True) # пользователь с id 1000 и группа 'games' должны существовать # а учетная запись должна иметь право на изменение прав # доступа, иначе будет ошибка 'PermissionError' print(f" Изменение прав доступа на папку: ‹{on_dir.resolve()}›,\n \ Папка создана:\n \ Владелец: {on_dir.owner()},\n \ Группа: {on_dir.group()}") shutil.chown('test_dir', user=on_uid, group='games') print(f" Папка: ‹{on_dir.resolve()}›,\n \ Изменение владельца:\n \ Владелец: '{on_dir.owner()}',\n \ Группа: '{on_dir.group()}'") mikl@mikl ~/0/Primer> python main.py username: mikl, uid: 1000 Изменение прав доступа на папку: ‹/home/mikl/003/Primer/test_dir›, Папка создана: Владелец: mikl, Группа: users Папка: ‹/home/mikl/003/Primer/test_dir›, Изменение владельца: Владелец: 'mikl', Группа: 'games'
Здесь, чтобы не искать и не думать о пресловутом id пользователя, мы сначала получаем имя пользователя запустившего терминал, а затем запрашиваем его id (username = os.getlogin() и on_uid = pwd.getpwnam(username).pw_uid). А затем выводим эти значения на экран, с помощью f-строки.
Далее вводим каталог, который нам необходимо создать. Перед созданием - на всякий случай проверяем - не создан ли он уже. Если нет - создаем его, включая все вложенные директории.
Проверяем, точнее перед изменения выводим группу и пользователя этого каталога на экран. И только после этого меняем группу. Владелец остаётся прежним. Потому что при создании директорий владелец будет всегда тот, кто запустил терминал. А мы его запросили в самом начале. Это была не обязательная операция. Просто, чтобы вы знали как это можно сделать.
Далее строкой shutil.chown меняем группу, и затем выводим изменения на экран, также с помощью f-строки.
6.2.6. Создание файлов и папок
6.2.6.1. Чтение и Запись файлов
Прежде всего необходимо понять, что в библиотеке OS нет команды для создания файла. А в библиотеке pathlib есть.
При попытке прочитать или записать файла мы всегда путаемся - как правильно это сделать. Первым делом вы скорее всего будете обращаться к команде open - что-то вроде следующего:
handle = open("test.txt", "r")
data = handle.readline() # read just one line
print(data)
handle.close()
Обратите внимание!
Дело в том, что при таком обращении в случае возникновения какой-либо ошибки при работе с файлом (ошибка доступа, невозможно открыть файл, нет такого файла и многие другие) вы не сможете закрыть этот файл. Он так и останется висеть в памяти ПК. Try excpet в этом случае хоть и обрабатывают исключения, однако, опять таки не закрывают сам файл.
Как же правильно это сделать? Через оператор with. Например, так.
with open("strukture.txt", "r") as file_handler: for line in file_handler: print(line)
Если необходимо сохранить данные в переменную, можно сделать так.
with open('strukture.txt', "r") as f: #lines = f.readlines() lines = f.read() print(lines) #for item in lines: # print(item, end = ' ')
Обратите внимание на комментарии! Комментариями отмечен вариант построчного получения данных и соответственно построчный вывод, т.к. в этом случае у вас будет список строк, а не одна большая строка.
Вот у нас есть комманда: with open ("data.txt", "r") as myfile. А что это за параметр "r"?
Если не указывать этот параметр, то файл будет открыть только для чтения. Этот параметр указывает на режим доступа к файлу.
Текстовые файлы можно использовать в следующих режимах:
- r - Только для чтения.
- w - Только для записи. Создаст новый файл, если не найдет с указанным именем.
- rb - Только для чтения (бинарный).
- wb - Только для записи (бинарный). Создаст новый файл, если не найдет с указанным именем.
- r+ - Для чтения и записи.
- rb+ - Для чтения и записи (бинарный).
- w+ - Для чтения и записи. Создаст новый файл для записи, если не найдет с указанным именем.
- wb+ - Для чтения и записи (бинарный). Создаст новый файл для записи, если не найдет с указанным именем.
- a - Откроет для добавления нового содержимого. Создаст новый файл для записи, если не найдет с указанным именем.
- a+ - Откроет для добавления нового содержимого. Создаст новый файл для чтения записи, если не найдет с указанным именем.
- ab - Откроет для добавления нового содержимого (бинарный). Создаст новый файл для записи, если не найдет с указанным именем.
- ab+ - Откроет для добавления нового содержимого (бинарный). Создаст новый файл для чтения записи, если не найдет с указанным именем.
Скорее всего вам понадобится пользоваться только 4 режимами: r, r+, rb и rb+.
В режимах 'w' и wb' происходит перезапись файла. В режимах 'w+' и 'wb+' файл в любом случае будет перезаписан. Однако, он также ведь открывается и для чтения. Поэтому для того, чтобы хоть что-то прочитать, сначала необходимо хоть что-то в него записать, иначе вы получите на выходе пустые данные!
Необходимо понимать, что в режимах 'w' и 'w+' добавление в файл данных не будет, будет происходить именно перезапись файла! Для добавления необходимо использовать другой режим. Например, 'r+', 'a', 'a+'.
Дело в том, что в режимах 'r+' и 'a+' вы можете как прочитать данные, так и дозаписать в файл какие-нибудь данные. Необходимо лишь устанавливать курсор в начало или конец файла file.seek(). А вот в режимах без плюса '+' вы можете либо только прочитать данные, либо только записать. Тоже самое, насчет использования плюса, касается всех режимов.
Во всех режимах добавления данных 'a', с плюсом и без, бинарный или нет - устанавливать курсор file.seek() в конец файла не обязательно. При старте, он сразу автоматически будет находится в конце файла для дозаписи. А вот во всех режимах 'r' с плюсом - обязательно контролируйте где находится курсор, ну или принудительно ставьте его в начало или конец файла. Иначе, при записи данных, вы рискуете потерять предыдущие данные.
Чтобы понимать как пользоваться всеми этими режимами, вам необходимо ознакомится ещё с несколькими важными понятиями.
И первое это метод file.seek(offset, whence) и переменная file.tell().
file.tell() получает текущую позицию указателя чтения/записи файла.
>>> text = 'This is 1st line\nThis is 2nd line\nThis is 3rd line\n'
>>> fp = open('foo.txt', 'w+')
>>> fp.write(text)
# 51
>>> fp.tell()
# 51
>>> fp.seek(0)
# 0
>>> fp.read(10)
# 'This is 1s'
>>> fp.tell()
# 10
>>> fp.read(15)
# 't line\nThis is '
>>> fp.tell()
# 25
>>> fp.close()
file.seek(offset, whence) перемещает указатель чтения/записи в файле.
- offset - смещение указателя чтения/записи файла на int байтов.
- whence - абсолютное позиционирование указателя в формате int.
Аргумент whence является необязательным и по умолчанию равен 0.
- 0 - смещает указатель на offset относительно начала файла.
- 1 - смещает указатель на offset относительно относительно текущей позиции.
- 2 - смещает указатель на offset относительно конца файла.
Использование whence имеет одну важную особенность. Значение 1 можно использовать только для бинарных файлов. Также и file.seek() использовать в обычных текстовых (не бинарных) файлах можно только следующими способами:
- file.seek(N, 0) - Где N ≥ 0.
- file.seek(0, 2).
Иначе вы рискуете получить 2 вида исключений: io.UnsupportedOperation и ValueError.
Ещё несколько важных моментов.
- Если файл открыт для добавления с помощью 'a' или 'a+', все операции file.seek() будут отменены при следующей записи.
- Если файл открыт только для записи в режиме добавления с использованием 'a', Этот метод по существу используется, но он остается полезным для файлов, открытых в режиме добавления с включенным чтением - режим 'a+'.
- Если файл открыт в текстовом режиме с помощью 't', то допустимы только смещения, возвращаемые функцией file.tell(). Использование других смещений вызывает неопределенное поведение.
>>> text = b'This is 1st line\nThis is 2nd line\nThis is 3rd line\n'
>>> fp = open('foo.txt', 'bw+')
>>> fp.write(text)
# 51
>>> fp.seek(20, 0)
# 20
>>> fp.read(10)
# b's is 2nd l'
>>> fp.seek(10, 1)
# 40
>>> fp.read(10)
# b's 3rd line'
>>> fp.seek(-11, 2)
# 40
>>> fp.read(10)
# b's 3rd line'
>>> fp.close()
Рассмотрим пример и чтения и дозаписи файла.
mikl ~/003/Primer $ nano main.py str2 = 'Многие думают о Lorem Ipsum.\n' lines = '' with open('strukture.txt', 'r+') as my_file: my_file.seek(0,0) # курсор может быть и не в начале, на всякий случай lines = my_file.read() print('Позиция:', my_file.tell()) print('Прочитанная информация:', lines) my_file.seek(0,2) print('Позиция:', my_file.tell()) my_file.write(str2) my_file.seek(0,0) lines = my_file.read() print('Позиция:', my_file.tell()) print('Файл был дозаписан:', lines) mikl ~/003/Primer $ python main.py Позиция: 31 Прочитанная информация: It is a long established fact. Позиция: 31 Позиция: 73 Файл был дозаписан: It is a long established fact. Многие думают о Lorem Ipsum.
Не забывайте, что в строках, которые вы записываете в файлы, нужны переносы строк. Иначе у вас все строки будут слитыми вместе!
Ну или можете вручную после каждой записи строки делать ещё одну запись одного переноса.
Чтение и запись файлов средствами pathlib.
Иногда бывает полезно быстро записать и считать некую техническую информацию о тех или иных объектах на английском языке. Для этого и предназначены методы чтения и записи данных данной библиотеки.
Метод Path.open().
Синтаксис команды:
Path.open(mode='r', buffering=-1, encoding=None, errors=None, newline=None)
Метод открывает файл, на который указывает путь path, как это делает встроенная функция open().
В моём файле strukture.txt с прошлых тестов остался некоторый текст. Часть на английском, часть на русском.
from pathlib import Path p = Path('strukture.txt') with p.open(encoding='utf-8') as f: print(f.readline())
Обратите внимание на то, что pathlib может некорректно или вообще не читать русский текст. Однако, файл читать будет!
Path.read_bytes() - возвращает содержимое бинарного файла. Файл при этом открывается и тут же закрывается.
from pathlib import Path
p = Path('test_binary_file')
p.write_bytes(b'Binary file contents')
print(p.read_bytes())
Метод Path.read_text.
Синтаксис команды:
Path.read_text(encoding=None, errors=None)
Возвращает декодированное содержимое файла в виде строки.
from pathlib import Path
p = Path('test_file')
p.write_text(b'Binary file contents')
print(p.read_text())
Метод Path.write_bytes() открывает файл, записывает байтовые данные и тут же закрывает его.
Синтаксис команды:
Path.write_bytes(data)
from pathlib import Path
p = Path('test_binary_file')
p.write_bytes(b'Binary file contents')
print(p.read_bytes())
Метод Path.write_text.
Синтаксис команды:
Path.write_text(data, encoding=None, errors=None, newline=None)
from pathlib import Path
p = Path('test_file')
p.write_text('Text file contents')
print(p.read_text())
6.2.6.2. Создание файлов и каталогов
Библиотека OS
Создание каталогов
Синтаксис команды os.mkdir:
os.mkdir(path, mode=0o777, *, dir_fd=None)
- path - имя каталога
- mode - режимом доступа к каталогу
- dir_fd - дескриптор каталога
Например:
import os
a = 'test'
os.mkdir(a, 0o755)
При создании нового каталога с помощью os.mkdir() все родительские каталоги должны уже существовать.
создать пустой каталог (папку)
os.mkdir("folder") # повторный запуск mkdir с тем же именем вызывает FileExistsError, # вместо этого запустите: if not os.path.isdir("folder"): os.mkdir("folder")
Функция os.path.isdir() вернет True, если переданное имя ссылается на существующий каталог.
Изменение текущего каталога на 'folder'.
mikl ~/003/Primer $ nano main.py
import os
os.chdir("folder")
# вывод текущей папки
print("Текущая директория изменилась на folder:", os.getcwd())
mikl ~/003/Primer $ python main.py
Текущая директория изменилась на folder: /home/mikl/003/Primer/folder
Предположим, вы хотите создать не только одну папку, но и несколько вложенных.
mikl ~/003/Primer $ nano main.py import os # вернуться в предыдущую директорию os.chdir("..")
# сделать несколько вложенных папок os.makedirs("nested1/nested2/nested3") mikl ~/003/Primer $ python main.py mikl ~/003/Primer $ ls -lha | grep -Ei nested1 drwxr-xr-x 3 mikl users 4,0K июл 24 15:19 nested1 mikl ~/003/Primer $ tree ./nested1 ./nested1 └── nested2 └── nested3 2 directories, 0 files
Библиотека pathlib
Синтаксис команды Path.mkdir:
Path.mkdir(mode=0o777, parents=False, exist_ok=False)
Если указан режим mode, он объединяется со значением umask, для определения режима файла и флагов доступа. Если путь уже существует, вызывается исключение FileExistsError.
- parents=True - создание всех отсутствующих подкаталогов, без учета указанного режима mode, имитируя команду POSIX mkdir -p.
- parents=False - Отсутствующие каталоги будут вызывать исключение FileNotFoundError.
- exist_ok=False - Если такой каталог уже существует вызывается исключение FileExistsError.
- exist_ok=True - исключения FileExistsError будут игнорироваться, команду mkdir -p, если предложенный путь не является существующим файлом.
Пример команды Path.mkdir.
from pathlib import Path
p = Path('folder1/folder2/folder3')
p.mkdir(parents=True)
Синтаксис команды Path.touch:
Path.touch(mode=0o666, exist_ok=True)
- Если указан режим mode, он объединяется со значением umask процесса для определения режима файла и флагов доступа.
- Если файл уже существует, функция завершается успешно.
- Если аргумент exist_ok имеет значение True, то его время модификации обновляется до текущего времени, в противном случае вызывается исключение FileExistsError.
Пример команды Path.touch.
from pathlib import Path
p = Path('test.txt')
p.touch(mode=0o644)
6.2.6.3. Жесткие и символьные ссылки
Символьные ссылки os.symlink.
Синтаксис команды os.symlink:
os.symlink(src, dst, target_is_directory=False, *, dir_fd=None)
- src - путь в файловой системе на который указывает ссылка
- dst - имя ссылки
- target_is_directory - в Windows ссылка как каталог
- dir_fd - дескрипторов каталогов
Пример каманды os.symlink:
import os
src = './strukture.txt'
dst = './test.txt'
os.symlink(src, dst)
# Очистим
os.unlink(dst)
Жесткая ссылка os.link.
Синтаксис команды os.link:
os.link(src, dst, *, src_dir_fd=None, dst_dir_fd=None, follow_symlinks=True)
- src - путь в файловой системе на который указывает ссылка
- dst - имя ссылки
- src_dir_fd - дескрипторов каталогов на который указывает ссылка
- dst_dir_fd - имя ссылки, дескрипторов каталогов
- follow_symlinks - переходить ли по ссылкам
Пример использования os.link:
import os
scr = 'test.txt'
dst = 'new.txt'
os.link(scr, dst)
Жесткая ссылка pathlib.Path.hardlink_to.
Синтаксис команды:
Path.hardlink_to(target)
- target - путь в файловой системе на который указывает ссылка. При этом путь куда сохранять ссылку вместе с именем ссылки берется из самого Path.
Пример использования pathlib.Path.hardlink_to:
from pathlib import Path
# Путь куда сохранить ссылку + название ссылки
# Ссылка сохранятеся в текущий каталог
p = Path('mylink')
# То, на что ссылается эта ссылка
p.hardlink_to('./strukture.txt')
Жесткая ссылка Path.link_to.
Синтаксис команды:
Path.link_to(target)
- target - название и место сохранения ссылки. При этом объект, на который должна ссылаться ссылка берется из самого Path.
Пример использования команды Path.link_to:
from pathlib import Path
p = Path('./strukture.txt')
p.link_to('mylink')
Символьные ссылки Path.symlink_to.
Синтаксис команды:
Path.symlink_to(target, target_is_directory=False)
- target - путь в файловой системе на который указывает ссылка. При этом путь куда сохранять ссылку вместе с именем ссылки берется из самого Path.
В Windows target_is_directory должен быть True (по умолчанию False), если целью ссылки является каталог. В POSIX значение target_is_directory игнорируется.
Пример использования команды:
from pathlib import Path
p = Path('./mylink')
p.symlink_to('./strukture.txt')
6.2.6.4. Булевы операции
Все булевы операции после выполнения возвращает либо «True», либо «False».
Булевы операции библиотеки os и os.path:
- os.path.exists(file_path) - проверить существование файла или директории
- os.path.isabs(path) - является ли путь абсолютным
- os.path.isfile(path) - является ли путь файлом
- os.path.isdir(path) - является ли путь директорией
- os.path.islink(path) - является ли путь символической ссылкой
- os.path.ismount(path) - является ли путь точкой монтирования
Булевы операции средствами pathlib
- Path.exists() - проверить существование файла или директории
- Path.is_dir() - вернет True, если путь path указывает на каталог, или символическую ссылку.
Значение False также возвращается, если путь не существует или является неработающей символической ссылкой. Метод может вернуть False при отсутствии доступа к директории или символической ссылке, указывающей на директорию. - Path.is_file() - вернет True, если путь path указывает на файл или символическую ссылку, указывающую на обычный файл. Метод вернет False, если путь указывает на файл другого типа.
Значение False также возвращается, если путь не существует или является неработающей символической ссылкой. Метод может вернуть False при отсутствии доступа к файлу или символической ссылке, указывающей на файл. - Path.is_mount() - Метода нет в Windows! Метод Path.is_mount() вернет True, если путь path является точкой монтирования в файловой системе, где смонтирована другая файловая система.
В POSIX функция проверяет, находится ли родительский путь path/.. на устройстве, отличном от path или path/.. и path указывают на однy и ту же ноду i-node на одном устройстве - это должно определять точки монтирования для всех вариантов Unix и POSIX. - Path.is_symlink() - вернет True, если путь path указывает на символическую ссылку, иначе вернет False.
Значение False также возвращается, если путь path не существует. Метод может вернуть False при отсутствии доступа к символической ссылке. - Path.is_socket() - вернет True, если путь path указывает на сокет Unix или символическую ссылку, указывающую на сокет Unix. Метод вернет False, если путь указывает на файл другого типа.
Значение False также возвращается, если путь не существует или является неработающей символической ссылкой. Метод может вернуть False при отсутствии доступа к сокету Unix или символической ссылке, указывающей на сокет. - Path.is_fifo() - ернет True, если путь path указывает на FIFO или символическую ссылку, указывающую на FIFO. Метод вернет False, если путь указывает на файл другого типа.
Значение False также возвращается, если путь не существует или является неработающей символической ссылкой. Метод может вернуть False при отсутствии доступа к FIFO или символической ссылке, указывающей на FIFO. - Path.is_block_device() - вернет True, если путь path указывает на блочное устройство или символическую ссылку, указывающую на блочное устройство. Метод вернет False, если путь указывает на файл другого типа.
Значение False также возвращается, если путь не существует или является неработающей символической ссылкой. Метод может вернуть False при отсутствии доступа к блочному устройству или символической ссылке, указывающей на блочное устройство. - Path.is_char_device() - вернет True, если путь path указывает на символьное устройство или символическую ссылку, указывающую на символьное устройство. Метод вернет False, если путь указывает на файл другого типа.
Значение False также возвращается, если путь не существует или является неработающей символической ссылкой. Метод может вернуть False при отсутствии доступа к символьному устройству или символической ссылке, указывающей на символьное устройство.
6.2.7. Переименование файлов и папок
Переименование файлов os.rename.
Синтаксис команды:
os.rename(src, dst, *, src_dir_fd=None, dst_dir_fd=None)
- src - исходное имя файла или каталога
- dst - новое имя файла или каталога
- src_dir_fd - исходный дескриптор каталога
- dst_dir_fd - новый дескриптор каталога
В Windows, если dst уже существует, всегда возникает ошибка FileExistsError.
Если имя dst уже существует, то операция может завершится с подклассом исключения OSError.
В Unix, если src - это файл, а dst - это каталог или наоборот, то поднимаются исключения IsADirectoryError или NotADirectoryError соответственно.
Если оба являются каталогами и dst пуст, то dst будет заменен без уведомления. Если dst является непустым каталогом, возникает OSError. Если оба являются файлами, то dst будет заменен без уведомления.
Операция может завершиться с ошибкой на некоторых разновидностях Unix, если src и dst находятся на разных файловых системах.
Пример использования.
import os
# Задаём исходный файл и тот, в который хотим переименовать
src, dst = 'strukture.txt', 'test.txt'
# Переименовываем
os.rename(src, dst)
# Присваиваем исходное имя и будущее переименованное
srcdir, dstdir = 'src_dir', 'dst_dir'
# Создаем исходный каталог
os.mkdir(srcdir)
# Переименовываем
os.rename(srcdir, dstdir)
# Удаляем, если не нужен
os.rmdir(dstdir)
Метод Path.rename.
Синтаксис команды:
Path.rename(target)
Метод Path.rename() переименует файл или каталог пути path в указанную цель target. Значение target может быть либо строкой, либо другим объектом пути.
Пример использования. С прошлого примера остался файл test.txt. Переименуем его обратно в strukture.txt.
from pathlib import Path
p = Path('test.txt')
p.rename('strukture.txt')
6.2.8. Перемещение файлов и папок
Переименование с перемещение replace.
Если пути к вашим папкам или файлам которые необходимо переместить находятся на одном уровне - команда работает подобно команде rename. Если между начальным и конечным путем имеются промежуточные директории файл или папка будут помещены именно туда с переименованием в конечное заданное значение. При наличии одинаковых файла с таким же именем, последний будет заменен.
Переименование с принудительной заменой os.replace.
Синтаксис команды:
os.replace(src, dst, *, src_dir_fd=None, dst_dir_fd=None)
Пример использования:
import os src, dst = 'strukture.txt', 'folder/test.txt' if not os.path.exists('folder'): # При отстутствии пути создаём его os.mkdir('folder') # Переименовываем и перемещаем os.replace(src, dst)
Переименование с принудительной заменой Path.replace.
Синтаксис команды:
Path.replace(target)
Пример использования:
from pathlib import Path src, dst = 'strukture.txt', 'folder/test.txt' if not Path(dst).parent.exists(): Path(dst).parent.mkdir(parents=True) p = Path(src) p.replace(dst)
Рекурсивно переместить файл или каталог shutil.move.
Синтаксис команды:
shutil.move(src, dst, copy_function=copy2)
- src - исходное место/путь копируемого файла
- dst - место/путь назначения нового файла
- copy_function - функция копирования файлов
Функция возвращает место назначения dst.
Если место назначения dst находится в текущей файловой системе, тогда используется os.rename(). В противном случае src копируется в dst с помощью функции, переданной в аргумент copy_function, а затем удаляется.
В случае символических ссылок, новая символическая ссылка, указывающая на цель src будет создана в или как dst и ссылка в src будет удалена.
Если задана функция copy_function, это должен быть вызываемый объект, который принимает два аргумента src и dst и будет использоваться для копирования src в dest, если функция os.rename() не может быть использована.
Если источником является каталог, вызывается shutil.copytree(), передавая ему функцию copy_function(). Функция копирования по умолчанию задана как shutil.copy2(). Использование функции shutil.copy() в качестве передаваемой функции copy_function позволяет выполнить перемещение успешно, когда также невозможно скопировать метаданные за счет отсутствия копирования каких-либо метаданных.
Пример использования
import shutil from pathlib import Path # Задаём исходную директорию, которую надо переместить и конечную src, dst = 'pkg', 'folder/pkgs' if not Path(dst).parent.exists(): # При отсутствии родительских директорий конечного пути создаём их Path(dst).parent.mkdir(parents=True) # Перемещаем с переименованием shutil.move(src, dst)
6.2.9. Удаление файлов и папок
Удаление символических ссылок os.unlink.
os.unlink(path, *, dir_fd = None)
- path - путь к ссылке
- dir_fd - дескриптор каталога
Пример использования os.unlink. Создадим ссылку и тут же удалим её.
import os
scr = 'test.txt'
dst = 'new.txt'
# Создаём ссылку
os.link(scr, dst)
# Тут же удаляем эту ссылку
os.unlink(dst)
Удаление файлов или символических ссылок pathlib.Path.unlink.
Path.unlink(missing_ok=False) - удаляет файл или символическую ссылку, указанную в пути path. Файл или символическая ссылка должны иметь соответствующее разрешение.
- missing_ok - игнорирование ошибок при обнаружении существования пути.
Если missing_ok = False (по умолчанию) и путь не существует, то вызывается исключение FileNotFoundError.
Если missing_ok = True, то исключение FileNotFoundError будет игнорироваться аналогично команде POSIX rm -f.
Пример использования Path.unlink.
from pathlib import Path
# Путь к ссылке с указанием её имени
p = Path('./mylink')
# Создаём ссылку
p.symlink_to('./strukture.txt')
# И тут же удаляем эту ссылку
p.unlink(missing_ok=True)
Удаление файлов os.remove.
Синтаксис команды.
os.remove(path, *, dir_fd=None)
- path - путь к файлу
- dir_fd - дескриптор каталога
Функция remove() модуля os удаляет путь path к файлу. Если путь является каталогом, возникает исключение IsADirectoryError.
Пример использования.
mikl@mikl ~/0/Primer> cp strukture.txt strukture-copy.txt mikl@mikl ~/0/Primer> nano main.py import os f = 'strukture-copy.txt' if os.path.isfile(f): os.remove(f) mikl@mikl ~/0/Primer> python main.py mikl@mikl ~/0/Primer> ls strukture-copy.txt ls: невозможно получить доступ к 'strukture-copy.txt': Нет такого файла или каталога
Работает.
Удаление каталога os.rmdir.
Синтаксис команды
os.rmdir(path, *, dir_fd=None)
- path - путь до каталога
- dir_fd - дескриптор каталога
Если директория path не существует или не является пустым каталогом, соответственно возникает исключение FileNotFoundError или OSError.
Для удаления не пустых директорий, лучше использовать функцию shutil.rmtree(). Но, о ней чуть позже.
Пример использования.
mikl@mikl ~/0/Primer> nano main.py import os path = './pkg2' os.mkdir(path, 0o777) mikl@mikl ~/0/Primer> python main.py mikl@mikl ~/0/Primer> ls -lha итого 40K drwxr-xr-x 4 mikl users 4,0K июл 30 12:07 . drwxr-xr-x 3 mikl users 16K июл 25 18:42 .. -rw-r--r-- 1 mikl users 142 июл 29 18:29 cmd.bat -rw-r--r-- 1 mikl users 107 июл 30 12:07 main.py drwxr-xr-x 4 mikl users 4,0K июл 25 23:17 pkg drwxr-xr-x 2 mikl users 4,0K июл 30 12:07 pkg2 -rwxr-xr-x 1 mikl users 73 июл 24 00:28 strukture.txt mikl@mikl ~/0/Primer> nano main.py import os path = './pkg2' if os.path.isdir(path): os.rmdir(path) mikl@mikl ~/0/Primer> python main.py mikl@mikl ~/0/Primer> ls -lha итого 36K drwxr-xr-x 3 mikl users 4,0K июл 30 12:08 . drwxr-xr-x 3 mikl users 16K июл 25 18:42 .. -rw-r--r-- 1 mikl users 142 июл 29 18:29 cmd.bat -rw-r--r-- 1 mikl users 125 июл 30 12:08 main.py drwxr-xr-x 4 mikl users 4,0K июл 25 23:17 pkg -rwxr-xr-x 1 mikl users 73 июл 24 00:28 strukture.txt
Удаление каталога Path.rmdir().
Метод Path.rmdir() удаляет каталог, указанный в пути path. Каталог должен быть пустым и иметь соответствующие разрешения.
Пример использования.
mikl@mikl ~/0/Primer> nano main.py import pathlib dirs = './pkg2' p = pathlib.Path(dirs) p.mkdir(mode=0o755, parents=True, exist_ok=True) mikl@mikl ~/0/Primer> python main.py mikl@mikl ~/0/Primer> ls -lha итого 40K drwxr-xr-x 4 mikl users 4,0K июл 30 12:14 . drwxr-xr-x 3 mikl users 16K июл 25 18:42 .. -rw-r--r-- 1 mikl users 142 июл 29 18:29 cmd.bat -rw-r--r-- 1 mikl users 163 июл 30 12:14 main.py drwxr-xr-x 4 mikl users 4,0K июл 25 23:17 pkg drwxr-xr-x 2 mikl users 4,0K июл 30 12:14 pkg2 -rwxr-xr-x 1 mikl users 73 июл 24 00:28 strukture.txt mikl@mikl ~/0/Primer> nano main.py import pathlib dirs = './pkg2' p = pathlib.Path(dirs) if p.is_dir(): p.rmdir() mikl@mikl ~/0/Primer> python main.py mikl@mikl ~/0/Primer> ls -lha итого 36K drwxr-xr-x 3 mikl users 4,0K июл 30 12:17 . drwxr-xr-x 3 mikl users 16K июл 25 18:42 .. -rw-r--r-- 1 mikl users 142 июл 29 18:29 cmd.bat -rw-r--r-- 1 mikl users 140 июл 30 12:17 main.py drwxr-xr-x 4 mikl users 4,0K июл 25 23:17 pkg -rwxr-xr-x 1 mikl users 73 июл 24 00:28 strukture.txt
6.2.10. Cписок файлов и директорий в папке
Первым будет os.listdir.
Синтаксис относительно простой.
os.listdir(path=".")
- path - путь в виде строки или дескриптор каталога
Данный метод возвращает список имен файлов в каталоге
Пример использования.
mikl ~/003/Primer $ nano main.py import os dirs = '.' output = os.listdir(dirs) for count, item in enumerate(output): print(f"{count+1} {item}") print('') dirs = './pkg' output = os.listdir(dirs) for count, item in enumerate(output): print(f"{count+1} {item}") mikl ~/003/Primer $ python main.py 1 main.py 2 cmd.bat 3 strukture.txt 4 pkg 1 test.py 2 compatible 3 tests
Рассмотрим ещё один метод - os.scandir.
Функция os.scandir() модуля os возвращает итератор entry_it объектов os.DirEntry, соответствующих записям в каталоге, заданный путем path. Записи приводятся в произвольном порядке, а специальные символы '.' и '..' не включены.
Использование os.scandir() вместо os.listdir() может значительно повысить производительность кода, который нуждается в информации о типе файла или атрибуте файла, поскольку объекты os.DirEntry предоставляют эту информацию, если операционная система предоставляет ее при сканировании каталога.
Все методы объекта os.DirEntry могут выполнять системный вызов, но для методов os.DirEntry.is_dir() и os.DirEntry.is_file() обычно требуется только системный вызов для символических ссылок. os.DirEntry.stat() всегда требует системного вызова в Unix, в Windows требуется только один системный вызов для символических ссылок.
Как только открыли итератор os.scandir() - обязательно его закрывайте - os.scandir.close(), чтобы закрыть итератор и освободить полученные ресурсы.
Для данного оператор можно всопользоваться оператором with, чтобы автоматически его закрыть по окончании работы.
Синтаксис команды.
os.scandir(path='.')
- path - путь к каталогу, может принимать str или bytes
Попробуем провести операцию аналогичную - os.listdir.
mikl ~/003/Primer $ nano main.py import os dirs = './' with os.scandir(dirs) as scan_dir: for count, entry in enumerate(scan_dir): print(f"{count+1} {entry.name}") mikl ~/003/Primer $ python main.py 1 main.py 2 cmd.bat 3 strukture.txt 4 pkg
Повторим результат с помощью Path.iterdir().
Метод Path.iterdir() вернет итератор объектов пути содержимого каталога, если путь path указывает на каталог.
mikl ~/003/Primer $ nano main.py import pathlib dirs = '.' p = pathlib.Path(dirs) for count, item in enumerate(p.iterdir()): print(f"{count+1} {item.name}") dirs = './pkg' print('') p = pathlib.Path(dirs) for count, item in enumerate(p.iterdir()): print(f"{count+1} {item.name}") mikl ~/003/Primer $ python main.py 1 main.py 2 cmd.bat 3 strukture.txt 4 pkg 1 test.py 2 compatible 3 tests
6.2.11. Рекурсивные операции
Такие операции начнём с рекурсивного удаления папки/каталога при помощи shutil.rmtree.
Синтаксис команды.
shutil.rmtree(path, ignore_errors=False, onerror=None)
- path - каталог для удаления
- ignore_errors - игнорирование ошибок во время удаления
- onerror - обработчик ошибок, возникающих в процессе удаления
Путь path должен указывать на каталог, но не символическую ссылку на каталог.
Если ignore_errors=True, то возникшие ошибки в результате неудачного удаления, будут игнорироваться. Если False или пропущено, такие ошибки обрабатываются путем вызова обработчика, указанного в onerror или, если он пропущен, они вызывают исключение.
Пример удаления директории с правами доступа «только для чтения» и использованием pathlib.
mikl ~/003/Primer $ cp -R pkg pkg2 mikl ~/003/Primer $ sudo chmod -R 444 ./pkg2 mikl ~/003/Primer $ ls -lha итого 40K drwxr-xr-x 4 mikl users 4,0K июл 30 12:46 . drwxr-xr-x 3 mikl users 16K июл 25 18:42 .. -rw-r--r-- 1 mikl users 142 июл 29 18:29 cmd.bat -rw-r--r-- 1 mikl users 261 июл 30 12:32 main.py drwxr-xr-x 4 mikl users 4,0K июл 25 23:17 pkg dr--r--r-- 4 mikl users 4,0K июл 30 12:46 pkg2 -rwxr-xr-x 1 mikl users 73 июл 24 00:28 strukture.txt mikl ~/003/Primer $ nano main.py import pathlib, stat import shutil def remove_readonly(func, path, _): pathlib.Path(path).cmod(stat.S_IWRITE) func(path) directory = './pkg2' shutil.rmtree(directory, onerror=remove_readonly) mikl ~/003/Primer $ sudo python main.py mikl ~/003/Primer $ ls -lha итого 36K drwxr-xr-x 3 mikl users 4,0K июл 30 12:48 . drwxr-xr-x 3 mikl users 16K июл 25 18:42 .. -rw-r--r-- 1 mikl users 142 июл 29 18:29 cmd.bat -rw-r--r-- 1 mikl users 261 июл 30 12:32 main.py drwxr-xr-x 4 mikl users 4,0K июл 25 23:17 pkg -rwxr-xr-x 1 mikl users 73 июл 24 00:28 strukture.txt
Функция os.walk - Рекурсивное получение имен файлов в дереве каталогов.
Синтаксис команды.
os.walk(top, topdown=True, onerror=None, followlinks=False)
- top - Верхний каталог для перебора.
- topdown - Направление обхода
- onerror - функция, которая сообщает об ошибке
- followlinks - переходить ли по символическим ссылкам
Возвращаемые значения: тройной кортеж:
- dirpath - путь к каталогу
- dirnames - список имен подкаталогов, кроме '.' и '..'
- filenames - список имен файлов
Имена в списках не содержат компонентов пути!
Чтобы получить полный путь, который начинается с top, необходимо к файлу или каталогу в dirpath, выполнить os.path.join(dirpath, name).
Пример использования. Раздельно подсчитаем общее количество файлов и общее количество папок которые набрались на данный момент в ./pkg
Но сначала проверим а сколько там действительно файлов и папок. И тут есть одно маленькое замечание.
Вы скорее всего уже по-Googl-лили и нашли несколько примеров с утилитой ls. Это не совсем правильный подход и результаты будут скорее всего ошибочны. Возьмите для примера маленькую вложенную директорию, всмысле с малым числом файлов и папок и посчитайте вручную, а затем предложенным Googl-ом вариантами. Уверен что результаты будут не совпадать.
Дело в том, что утилита ls смотрит на все файлы без исключений, включая '.' и '..' и многие скрытые файлы и папки. Например у Python-скриптов после выполнения может появлятся директория __pycache__ и даже автоматически удаляться.
Что тогда делать?
Проблема решается элементарно.
Воспользуемся конвеером 2 комманд: find и wc.
Find предназначена для поиска файлов и каталогов на основе специальных условий. Её можно использовать в различных обстоятельствах, например, для поиска файлов по разрешениям, владельцам, группам, типу, размеру и другим подобным критериям.
Если грубо - то она пропускает такие вещи как '.' и '..'.
В ней легко задать критерий пропуска скрытых файлов или скрытых папок.
WC - это утитита для подсчета количества строк, слов, символов и байтов.
У find имеется такой параметр как type - тип результатов поиска
- f - файлы
- d - директории
Ещё есть iname - наименование поиска. Однако, мы будем искать все файлы или директории без исключений.
Команда возвращает путь к полученному объеку.
У команды wc есть такой параметр как « l » - подсчет количества строк.
Этого будет вполне достаточно.
mikl ~/003/Primer $ # Подсчитаем количество файлов в этой директории
mikl ~/003/Primer $ find ./ -type f | wc -l
23
mikl ~/003/Primer $ # Подсчитаем количество вложенных директорий
mikl ~/003/Primer $ find ./ -type d | wc -l
6
mikl ~/003/Primer $ # Включая текущую директорию - действительно +1 директория
А теперь пример Python-скрипта.
mikl ~/003/Primer $ nano main.py import os dir_count = 0 file_count = 0 on_dir = './' for root, dirs, files in os.walk(on_dir, topdown=False): file_count+=len(files) dir_count+=len(dirs) print(f"Files count = {file_count},\nDir count = {dir_count}") mikl ~/003/Primer $ python main.py Files count = 23, Dir count = 5
Как видите - результаты совпадают.
Либо мы можем тоже самое записать в тернарных операторах.
import os
on_dir = './'
file_count = sum([len(x) for _, _, x in os.walk(on_dir, topdown=False)])
dir_count = sum([len(x) for _, x, _ in os.walk(on_dir, topdown=False)])
print(f"Files count = {file_count},\nDir count = {dir_count}")
А теперь рассмотрим как выглядят рекурсивные операции в pathllib.
Разница между Path.glob() и Path.rglob() в том, что в первом случае для включения рекурсии необходимо указывать «**» 2 звездочки в шаблоне поиска. В то время как в rglob рекурсивный поиск включен по умолчанию. Вообще, рекурсивный поиск по под-каталогам рекомендуется делать именно через rglob, потому как в нём он оптимизирован специально для этой задачи, в то время как через glob такая операция может притормаживать систему.
Прежде, чем мы рассмотрим Path.glob() и Path.rglob() необходимо пояснить несколько моментов насчет шаблонов поиска, которые можно использовать в этих методах.
Базовые шаблоны для поиска:
- « * » - поиск всех файлов и папок одновременно
- « . » - поиск только всех каталогов
- « *.* » - поиск только всех файлов
Шаблоны поиска могут использовать простые регулярные выражения, как в bash. Однако, не все конструкции могут работать. Применительно только как к наименованиям.
В папке «./pkg/» я создал директорию «search» и несколько файлов, а также расположил в одном из под-каталогов .png изображение.
Примеры работы с данными методами вы можете увидеть в конце этой главы. А сейчас продолжим разговор о шабонах поиска.
В Path.glob шаблоны поиска могут выглядеть следующим образом.
- Path('pkg/search/').glob('*.py')
- Path('pkg/').rglob('*.png')
- Path('pkg/').rglob('[0-9]*.txt')
- Path('pkg/').rglob('[0-9].txt')
- Path('pkg/').rglob('[0-9]?.txt')
- И многие другие варианты.
Первый на очереди Path.glob(pattern).
Метод Path.glob() возвращает список всех файлов любого типа, соответствующий заданному шаблону pattern, расположенных в каталоге, указанном в пути path.
Шаблон '**' указывает на рекурсивный обход в глубину каталога, указанного в пути path, и всех его подкаталогов.
Например найдём все «.py»-файлы нешего «./pkg/tests» каталога и выведем их на экран. Ну а чтобы не запутаться что где находится, сделаем вывод построчно.
Для более краткого вывода я вручную удалил несколько скриптов, так что общее количество файлов теперь изменилось.
mikl ~/003/Primer $ nano main.py
from pathlib import Path
paths = list(map(str, sorted(Path('.').glob('**/*.py'))))
for x in paths: print(x)
mikl ~/003/Primer $ python main.py
pkg/tests/__init__.py
pkg/tests/status.py
pkg/tests/test-abs-path.py
pkg/tests/test-pathlib-1.py
pkg/tests/test-pathlib-2.py
pkg/tests/test.py
Метод Path.rglob(pattern) - работает подобно вызову метода Path.glob() с добавлением конструкции '**/' перед заданным относительным шаблоном pattern, тем самым по умолчанию производит рекурсивный поиск файлов, соответствующего шаблона.
Т.е. тот же поиск «.py» файлов, например в той же директории «./pkg/tests» каталога будет выглядеть на пару символов меньше.
mikl ~/003/Primer $ nano main.py
from pathlib import Path
paths = list(map(str, sorted(Path('.').rglob('*.py'))))
for x in paths: print(x)
mikl ~/003/Primer $ python main.py
pkg/tests/__init__.py
pkg/tests/status.py
pkg/tests/test-abs-path.py
pkg/tests/test-pathlib-1.py
pkg/tests/test-pathlib-2.py
pkg/tests/test.py
А теперь посмотрим как рекурсивно раздельно подсчитать количество файлов и количество папок в заданной директории и сравним с результатом конвеера с find и wc.
Ниже приведённый пример конструкций тернарных операторов можно значительно упростить. Обычно делают гораздо более простые конструкции или используют list и map.
Такие конструкции приведены строго в учебных целях - чтобы показать как ими пользоваться в случае использования внутри списка.
mikl ~/003/Primer $ nano main.py from pathlib import Path on_dir = './' # Вообще условие положено ставить вместе с else перед циклом, но так тоже будет работать. Однако, else уже нельзя ставить в конце file_count = sum([1 for x in list(Path(on_dir).rglob('*')) if x.is_file()]) dir_count = sum([1 for x in list(Path(on_dir).rglob('*')) if x.is_dir()]) # Лучше если эти 2 строки будут выглядеть так: # file_count = sum([ 1 if x.is_file() else 0 for x in list(Path(on_dir).rglob('*')) ]) # dir_count = sum([ 1 if x.is_dir() else 0 for x in list(Path(on_dir).rglob('*')) ]) print(f"Files count = {file_count},\nDir count = {dir_count}") mikl ~/003/Primer $ python main.py Files count = 18, Dir count = 5 mikl ~/003/Primer $ find ./ -type f | wc -l 18 mikl ~/003/Primer $ find ./ -type d | wc -l 6
В последней строке количество директорий, включая текущую - поэтому -1. Результаты совпадают.
А вот так можно все эти конструкции тернарных операторов значительно упростить.
from pathlib import Path
on_dir = './'
file_count = len(list(Path(on_dir).rglob('*.*')))
dir_count = len(list(Path(on_dir).rglob('.')))-1
print(f"Files count = {file_count},\nDir count = {dir_count}")
Результат будет тот же.
Красиво и коротко. Не правда ли ?
К сожалению, с os и os.path такой трюк не пройдёт, т.к. там чаще всего возвращаются не списки, а кортежи разной размерности.
А теперь рассмотрим примеры работы с шаблонами поиска Path.glob() и Path.rglob().
Структура добавленного search каталога выглядит следующим образом.
mikl ~/003/Primer $ tree ./pkg/search/
./pkg/search/
├── 1.txt
├── 22.txt
├── 3a.txt
├── test.py
├── text1.txt
└── text.txt
0 directories, 6 files
Обратите внимание на наименования файлов. Это сделано специально для демонстрации.
Откроем main.py файл и запишем в него знакомые шаблоны поиска с небольшой модификацией для красивого вывода результата и более быстрой обработки результата поиска.
mikl ~/003/Primer $ nano main.py #!/usr/bin/env python3 # -*- coding: utf-8 -*- from pathlib import Path paths = list(map(str, sorted(Path('pkg/search/').glob('*.py')))) print("Path('pkg/search/').glob('*.py'):", end=' ') for x in paths: print(x, end=' ') print("\nPath('pkg/').glob('**/*.png'):",end=' ') paths = list(map(str, sorted(Path('pkg/').rglob('*.png')))) for x in paths: print(x, end=' ') print("\nPath('pkg/').glob('**/[0-9]*.txt'):", end=' ') paths = list(map(Path, sorted(Path('pkg/').rglob('[0-9]*.txt')))) for x in paths: print(x.name, end=' ') print("\nPath('pkg/').rglob('[0-9].txt'):", end=' ') paths = list(map(Path, sorted(Path('pkg/').rglob('[0-9].txt')))) for x in paths: print(x.name, end=' ') print("\nPath('pkg/').rglob('[0-9]?.txt'):", end=' ') paths = list(map(Path, sorted(Path('pkg/').rglob('[0-9]?.txt')))) for x in paths: print(x.name, end=' ') print('')
После запуска изменённого main.py файла мы увидим следующий результат.
mikl ~/003/Primer $ python main.py
Path('pkg/search/').glob('*.py'): pkg/search/test.py
Path('pkg/').glob('**/*.png'): pkg/compatible/py-imports-logo.png
Path('pkg/').glob('**/[0-9]*.txt'): 1.txt 22.txt 3a.txt
Path('pkg/').rglob('[0-9].txt'): 1.txt
Path('pkg/').rglob('[0-9]?.txt'): 22.txt 3a.txt
 и Path.rglob()")
6.3. Вывод.
Исходя из приведенных сравнений библиотек - мы получаем, что pathlib объединяет в себе часто используемые функции двух стандартных модулей os и os.path, а так же стандартную функцию open() для чтения и записи файлов. Этот модуль гораздо компактнее, быстрее и эффективнее, а главное в нём значительно больше различных методов и операций над файлами и папками. Использовать его намного легче, чем модули os и os.path. Последовательное выполнение комманд через точку друг за дружкой намного упрощают взаимодействие с модулем, по сравнению с вложенными вызовами os и os.path.
Думаю, pathlib стоит взять на вооружение - особенно если вас волнует корректное взаимодействия с путями в разных ОС. И да - библиотека - КРОСПЛАТФОРМЕННА.
Для большей наглядности причин за использование данной библиотеки скажу вот что.
Бибиотека os иногда может карёжить пути в Windows-е.
Происходит это достаточно просто.
Вы наверно встречали такое, что записав некий файл с русским наименованием в Windows - загрузившись в Linux вы не могли прочитать его название ?
Дело в том, что Windows по умолчанию использует ASCII. Linux же напротив - использует по умолчанию UTF-8.
Поэтому файл в первой кодировке не всегда удаётся корректно прочитать в Linux-е. Однако это далеко не вся проблема!
Скопировав бездумно некое название с интернета и присвоив его вашему файлу - вы наверняка записываете его далеко не в кодировке ASCII, а может даже и не в UTF-8.
Результат такого взаимодействия - некорректное чтение имени файла или имени директории, причем, как в Windows, так и в Linux.
В Python же скрипте мы обнаружим несколько неприятных ошибок, которые врядли удасться адекватно исправить.
Например - при правильном имени файла или папки - исключение FileNotFoundError - такого файла не существует.
А иногда всё до боли намного проще.
Ошибка ну просто смешная - os и os.path не могут прочитать лишний обратный слеш под-директории, в которой находится файл или нужная вам папка. Добавляете этот самый обратный слеш в имя файла или папки, даже 2 обратных слеша, чтобы не экранировать скобки строки - и опять получаете предыдущее исключение.
Более того - слеш надо поставить правильный - в зависимости от ОС.
- / - прямой в Linux
- \\ - обратный в Windows
Узнать его можно с помощью - os.sep.
mikl ~/003/Primer $ nano main.py
import os
print(os.sep)
mikl ~/003/Primer $ python main.py
/
pathlib-у же напротив - абсолютно до лампочки как вы прописали путь. Она автоматически конвертирует его в правильный формат с правильным разделителем пути.
7. Задачи с решениями
Рассмотрим несколько задач с решениям. Решения будут не сразу - а с объяснениями, чтобы вам была понятна - причина того или иного решения или подхода.
7.1. Задача №1.
Задача для Windows.
-
Получить список доступных дисков в системе.
К сожалению, определить тип диска без дополнительных pip библиотек не удасться. Точнее удасться, но работать такой способ будет либо только в Win 7, либо только в Win 10. Поэтому ограничимся только списком доступных дисков.
Чтобы определить доступен ли тот или иной диск, нам необходимо знать его букву. Т.е. в самом начале нам нужны не сами диски, а пока возможные значения букв дисков. Достаточно будет просто написать английский алфавит в прямой последовательности.
Алфавит всегда будет неизменчивым и сразу в правильном для нас виде. Однако, писать его вручную не совсем удобно, а тем более проделывать далеко не одну такую операции в больших проектах - может вас попросту запутать - и вы наделаете множество ошибок, которые потом будет сложно исправить. Поэтому создадим алфавит немного по другому.
Есть такая функция chr. Она преобразует число в символ Юникода.
Прописные символы английского алфавита находятся в диапазоне от 65 до 91 включительно.
Задачу можно решить как с помощью цикла for, так и с помощью map - обработки последовательностей без цикла. В этой функции через запятую необходимо указать именно наименование выполняемой функции, т.е. без круглых скобов (); а также итерируемую последовательность. т.е. последовательность, которую можно перебрать в цикле.
Выглядит это следующим образом.
alphabet1 = ''.join([chr(x) for x in range(65,91)])
alphabet2 = ''.join(list(map(chr, range(65,91))))
print(alphabet1)
print(alphabet2)
Результат в обоих случаях будет абсолютно одинаковый.
Тепер нам понадобится библиотека pathlib. А точнее одна её функция - Path.exists() - проверка существования пути в файловой системе.
Далее мы конечно могли бы воспользоваться функциями map и/или filter, но в этом случае код может неизбежно в разы вырасти и стать крайне громоздким. (Это уже проверено). В этом случае, конечно, код само собой будет без единого цикла, возможно, даже более красивым. Однако, иногда, таких конструкций стоит избегать.
Т.е. вложенных друг в друга генераторов!
Это может вас сильно запутать и вы скорее всего ошибётесь: где какие скобки ставить, где делать вызов, а где вставлять присвоение lambda функции и многие другие.
Чаще всего такие подходы применяют в тех случаях, когда код возможно значительно упростить именно за счет вызова выполнения генераторов функций, а не самих функции. Т.е. именно за счет выполнения одного генератора, а не вложенных друг в друга генераторов.
Это конечно не говорит о том, что такие подходы нельзя использовать - наоборот. Просто использовать их надо осторожно, т.е. с умом. Точнее думать - когда такой подход упростит ваше решение, а когда наоборот - усложнит.
Здесь соблюдается один единственный главный принцип - чем проще, тем лучше.
Поэтому именно в этом лучше не пренебрегать наипростейшими циклами с тернарными операторами.
Есть ещё один нюанс.
Генераторы полезны там, где имеется большой объем данных. Ведь в этом случае у вас не возникнет ошибки переполнения памяти.
Ктстати, говоря в одной из глав выше я упоминал, что внутри циклов, при использовании тернарных операторов условие необходимо ставить перед самим циклом. Однако, в этом случае вам придётся прописывать оба исхода условия - и при True и при False. Иначе без else у вас будет ошибка синтаксиса. Но, если поставить условие после цикла - тогда использование else отпадает как таковое. Иначе в последнем случае у вас опять будет ошибка синтаксиса.
Выглядит это следующим образом.
drives = [f'{d}:' for d in alphabet2 if Path(f'{d}:').exists()]
Итоговое решение будет выглядеть следующим образом.
from pathlib import Path def main(): alphabet1 = ''.join([chr(x) for x in range(65,91)]) alphabet2 = ''.join(list(map(chr, range(65,91)))) print(alphabet1) print(alphabet2) drives = [f'{d}:' for d in alphabet2 if Path(f'{d}:').exists()] print(drives) if __name__ == '__main__': main()
Как видите - alphabet1 и alphabet2 ничем друг от друга не отличаются. Здесь вполне можно применить map.
А вот что касается drives, то map и filter неизбежно увеличат громоздкость кода и значительно усложнят читабельность и как факт понимание его работы. Поэтому применён только цикл.
7.2. Задача №2.
Я заранее поместил в каталог «./pkg» файл «cmd.bat» несколько раз в разные случайные под-папки.
-
Найти в папке «./pkg» все файлы с расширением «cmd.bat» и удалить их.
Усложнение: не использовать циклы..
Если вы думаете, что сможете сделать последовательный вызов, что-то вроде: «pathlib.Path().rglob('*.bat').unlink()», то вы глубоко заблуждаетесь.
У вас просто выйдет исключение AttributeError.
Это исключение говорит о том, что и метод glob и rglob библиотеки pathlib возвращают генератор, а не список найденных путей.
Допустим, вы обернули генератор в список list - например, так: «p = list(Path('./pkg').rglob('*.bat')).unlink(missing_ok=True)».
Однако, вам всё равно не удасться применить метод unlink() к полученному списку. У вас опять возникнет тоже самое исключение AttributeError.
Последнее исключение как раз и говорит вам о том, что оъект типа 'list' не не имеет аттрибута unlink().
На самом деле задача решается буквально в 2 строки. Однако, для наглядности мы с вами рассмотрим каждый этап по отдельности и в отдельных строках для понимания каждой команды.
Сначала убедимся, что rglob возвращает именно генератор, а не результат.
Откроем консоль и запустим python.
mikl ~/003/Primer $ python
>>> from pathlib import Path
>>> p = Path('./pkg').rglob('*.bat')
>>> print(p)
‹generator object Path.rglob at 0x7fbf24835850›
Теперь обернем переменную «p» в список и посмотрим, что у нас получилось на выходе. Продолжаем ввод.
>>> p = list(p)
>>> print(p)
[PosixPath('pkg/cmd.bat'), PosixPath('pkg/compatible/subpackage_b/cmd.bat'), PosixPath('pkg/search/cmd.bat'), PosixPath('pkg/tests/cmd.bat')]
Нашли необходимые файлы. Теперь, чтобы решить задачу необходимо понимать 2 вещи: что такое лямба функции и что такое map.
Лямбда-функция — это небольшая анонимная функция, которая принимает любое количество аргументов, но имеет только одно выражение. Лямбда-функции возвращают объект, который назначен переменной или используется как часть других функций.
Т.е. лямбда функция - это буквально короткая однострочная функция - вроде тернарного оператора, т.е. упрощения, но для функций.
Функция map применяет заданную в неё функцию по её наименованию к каждому элементу итерируемой последовательности, которая задана 2 аргументом.
Например, применить к списку типа list метод int.
Допустим у меня есть список значений, но в строковом виде. Необходимо их быстро привести к целочисленному типу int.
a = ['1', '2', '3', '4', '5']
b = list(map(int, a))
print(a)
print(b)
x = list(map(type, a))
y = list(map(type, b))
print(x)
print(y)
При выполнении скрипта с этим кодом, мы увидим следующий результат.
['1', '2', '3', '4', '5']
[1, 2, 3, 4, 5]
[‹class 'str'›, ‹class 'str'›, ‹class 'str'›, ‹class 'str'›, ‹class 'str'›]
[‹class 'int'›, ‹class 'int'›, ‹class 'int'›, ‹class 'int'›, ‹class 'int'›]
Теперь поговорим о сочетании map и лямбда функций.
Если вы помните map выполняет заданную функцию. Лямбда же функция по сути сначала возвращает не результат и ссылку на функцию. Таким образом её вполне можно вставлять в качестве первого аргумента.
Например, просто возвести список значений в квадрат.
Да, мы могли бы поступить следующим образом.
a = [1, 2, 3] b = [] for x in a: b.append(x*x)
Мы даже вполне могли бы упростить до одного терарного оператора.
a = [1, 2, 3]
c = [x*x for x in a]
А могли бы сделать и так.
a = [1, 2, 3]
d = list(map(lambda x: x*x, a))
Результат во всех случаях будет абсолютно одинаковый.
Теперь когда вам понятно как использовать сочетния map и lambda стоит подчеркнуть ещё один нюанс.
При вызове метода Path.unlink() нам ничего не будет возвращено, т.е. конечный список должен быть пустым. Т.е. можно этот список не присваивать никакой переменной, а просто вызвать и всё.
Итак, полный код решения.
mikl ~/003/Primer $ nano main.py
from pathlib import Path
p = list(Path('./pkg').rglob('*.bat'))
list(map(lambda x: x.unlink(missing_ok=True), p))
# Не обязательно - проверяем результат повторным поиском
p = list(Path('./pkg').rglob('*.bat'))
# Просто выведем результат повторного поиска на экран, он должен быть пустым
print(p)
mikl ~/003/Primer $ python main.py
‹generator object Path.rglob at 0x7fbf24835850›
[PosixPath('pkg/cmd.bat'), PosixPath('pkg/compatible/subpackage_b/cmd.bat'), PosixPath('pkg/search/cmd.bat'), PosixPath('pkg/tests/cmd.bat')]
[]
7.3. Задача №3.
Первые две задачи были достаточно простыми. Однако, они направлены с учебной целью на наиболее частые действия, которые требуются в разных ОС. Теперь рассмотрим немного более сложную и одновременно простую задачу.
Представьте себе ситуацию, что ваш рабочий сервер сгорел и контролера доменов с Active Directory больше нет. Пусть для примера будет блок питания.
Бухгалтерия не выделяет средства ни на починку, ни на ремонт.
Более того - в вашей организации локальный сервер, даже в качестве файлового, больше не нужен, потому что бухгалтерия перешла на облачные технологии и облачную защиту. А все пользователи сети вашей организации давно начали пользоваться удалёнными базами данных по специальному доступу (приказ сверху).
Большинство всех современных организаций переходят на облачные технологии. Так что, такая ситуация вполне нормальна для современных реалей жизни.
А может быть так, что количество денег в вашей оранизации может с трудом хватать на зарплаты сотрудников и бухгалтерия просто не может выделить ни цента даже на починку.
На самом деле причина не так важна. Важны последствия. Ведь теперь у вас масса рабочих ПК с непонятными наборами пользователей. Причём пароли не так важны, ведь их легко можно обойти, что в Windows, что в Linux.
Главное - это теперь это всё надо как-то разрулить.
Собрать со всех ПК простую информацию о системах при помощи библиотеки platform не проблема.
Но ведь её будет не достаточно.
Если имя активного пользователя можно узнать с помощью кросплатформенной команды «whoami», то с остальным надо разбираться как-то по другому.

И вот тут на арену выходит задача-помошник.
-
Получить список пользователей ОС: и Windows, и Linux.
В Windows список учетных записей и активной учетной записи. Не сетевых пользователей, а локальных.
В Linux просто получить список пользователей ОС и пользователя вошедшего в систему.
Задача кажется довольно сложной и вы, наверняка, как и я изначально, будете искать способы определения списка учетных записей обоих систем.
Да, вы можете это проделать с помощью различных дополнительных библиотек. А в случае когда не сможете - обратитесь за помщью к C++.
Возможно даже найдёте один из спосбов IDE C++ Builder - вроде вот этого.
Однако, тут есть 2 большие проблемы.
-
Решение не кросплатформенно.
Найдя решение для одной системы оно не годится для другой.
Сегодня вы работаете в Windows - завтра по приказу сверху переходите на отечественное ПО Linux. -
К сожалению, практически все варианты решений любого языка программирования имеют проблемы с кодировкой.
Проблема не заметна пока вы используете только вывод данных в консоль или командную строку. Однако, как только вы попытаетесь записать полученные данные в файл - неизбежно столкнётесь с иероглифами.
Ни один из найденых мною способов преобразования wchar_t в string не работает и в файл сохраняется полная ерунда.
Правильнее говоря - преобразования из кодировки строки CP1251 в UTF-8.
В последнем можете убедиться сами - скачайте всю папку целиком и запустите cmd.bat файл, затем введите: «getusers.exe». При вызове из командной строки - всё будет нормально отображаться. Как только вы попытаетесь перехватить результат выполнения программы в Python (например, с помощью Subprocess или os.popen) - получите на выходе только иероглифы.
Один НЮАНС!
Иероглифы будут только в том случае, если на проверяемом ПК имена пользователей на русском языке.
Если на английском или латиницей - проблем не будет.
Вызовы перехватывают за тем, чтобы их как-то использовать - например, собрать всю информацию и из platform и с помощью вашей консольной Python-программы в один небольшой лог-файл.
На самом деле решение довольно примитивное - всем известное, однако, не все понимают, что нижеуказанный подход намного проще библиотечных и системных вызовов разлиных функций и программ. А главное - в разы быстрее, потому что выдаёт на выходе абсолютно такую же информацию.
Более того - решение уже будет кросплатформенным и относится не только к языку Python.
Но обо всём по порядку.
Для начала дайте определение каталогу пользователей.
Ему можно дать много разных определений, но самое главное на мой взгляд каталог пользователей - это место, где находятся все папки домашних деректорий пользователей по их именам в системе.
Т.е. в этой папке находятся только домашние папки пользователей, которые могут войти в систему с теми или иными правами доступа.
Закрадывается вопрос - почему бы получить список пользователей отсюда?
Да - возможно, но есть нюансы.
Тогда возникает второй вопрос - что такое домашний каталог пользователя ?
Домашний каталог — это личный каталог пользователя в ОС, где находятся его данные, настройки и т. д.
Т.е. в имени директории содержится имя активного пользователя?
Да - действительно это так. Причём выглядит абсолютно одинаково - что в Windows, что в Linux.
Теперь вернёмся к нюансам.
В Linux у вас не будет проблем - просканируйте директорию /home - для списка пользователей, а для активного пользователя просто проанализируйте переменную-ссылку на домашний каталог текущего пользователя. Этого будет достаточно.
В Windows в директории пользователей храняться не только существующие учетные записи, но и так называемые - блокированные уетные записи, Default учетные записи, стандартные встроеные учетные записи администраторов, скрытые учетные пользователей и другие.
В последнем случае - это не значит что вы сможете во все эти учетные записи войти.
Получается, что хоть парочки из таких учетных записей именно в Windows необходимо отфильтровывать.
Остаётся только один вопрос: как сделать решение кросплатформенным?
Сегодня мы с вами решим и эту проблему.
Первым делом давайте заведём список, в который мы будем вносить все имена пользователей, которых хотим исключить из конечного списка.
exclude_users = ['All Users', 'Default', 'Default User', 'desktop.ini', 'Public', 'Все пользователи', 'Intel', 'AMD']
Это базовые пользователи, которые чаще всего просто скрыты и не видны при простом открытии папки: C:\users\, за исключением общей папки.
Именно в этот список вы и можете вносить любых пользователей или папки, которые вы хотите исключить из поиска.
Далее нам нужен домашний каталог пользователя от которого и будем крутиться.
p = pathlib.Path.home()
Для вывода активного пользователя в любой ОС в pathlib достаточно запросить имя полученной директории.
print(p.parts[-1], p.name)
Здесь мы видим 2 способа:
-
p.parts[-1] - возвращает кортеж частей путей на основе разделителя путей для данной ОС.
И в конце берем срез кортежа - только последнюю часть пути. - p.name - стандартное базовое имя пути. Наиболее частое и правильное решение.
Чтобы обратиться к каталогу пользователей необходимо всего лишь обратиться к родительской директории.
print(p.parent)
Чтобы получить список пользователей системы и отфильтровать его, сначала необходимо получить список всех пользователей системы.
all_users = list(map(lambda x: x.name, list(p.parent.iterdir())))
# all_users = list(map(lambda x: x.name, list(p.parent.glob('*'))))
В комментарии я указал второй способ получения списка всех пользователей системы. Здесь необходимо обратить внимание только на строку поиска Path.glob('*'). Поиск должен быть именно всех файлов и папок, но не рекурсивный, иначе вы рискуете получить исключение IndexError.

Теперь можно получить список доступных пользователей системы и одновременно исключить exclude_users.
pc_users = [x for x in all_users if not x in exclude_users]
print(pc_users)
Ну и посмотрим теперь на весь код целиком.
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import pathlib exclude_users = ['All Users', 'Default', 'Default User', 'desktop.ini', 'Public', 'Все пользователи', 'Intel', 'AMD'] def main(): global exclude_users p = pathlib.Path.home() print(p.parts[-1], p.name) print(p.parent) all_users = list(map(lambda x: x.name, list(p.parent.iterdir()))) # all_users = list(map(lambda x: x.name, list(p.parent.glob('*')))) pc_users = [x for x in all_users if not x in exclude_users] print(pc_users) if __name__ == '__main__': main()
А теперь посмотрим как этот код выполняется в Windows 10.

8. Немного «unittest»
Если мы затронули тему пакетирования package, соответственно нельзя обойти стороной и тестирование своих модулей.
Представьте, что вы написали какую-либо программу, а теперь хотите проверить, правильно ли она работает. Что вы для этого сделаете? Скорее всего, вы запустите её несколько раз с различными входными данными, и убедитесь в правильности выдаваемого ответа.
А теперь вы что-то поменяли и снова хотите проверить корректность программы. Запускать ещё несколько раз? А если потом снова что-то поменяется? Нельзя ли как-то автоматизировать это дело?
Оказывается, можно. В Python встроен модуль unittest, который поддерживает автоматизацию тестов, использование общего кода для настройки и завершения тестов, объединение тестов в группы, а также позволяет отделять тесты от фреймворка для вывода информации.
На самом деле о тестах можно говорит очень много, однако, я и сам пока что не так много о них знаю. Поэтому оставлю вам здесь несколько наиболее важных ссылок, на мой взгляд.
- Наиболее полное описание возможностей модуля
- Базовая «Python» документация
- Русифицированная «Python» документация
- Здесь немного больше базовой информации, чем в «Python» документации
9. О Python в Windows 7, 10 и выше, а также WINE.
Для того, чтобы получить доступ к Windows путям библиотеки pathlib я воспользуюсь следующим методом внутри Linux.
Помните, что такой метод позволит лишь попробовать запустить какой либо код, так сказать испытать его в действии без загрузки самой ОС, напрямую в Linux. При этом он будет работать в Windows, но компиляция этого кода при помощи библиотек: nuitka, pyinstaller, Cython, py2exe и других - в wine не даёт гарантии работоспособности таких exe файлов в Windows.
Помните, что не всякий код можно будет проверить на работоспособность таким быстрым способом в Linux.
Для того, чтобы получить доступ к Windows путям библиотеки pathlib в Linux, я скачаю портативную версию Python с сайта sourceforge.net. Версии 3.8.9 будет достаточно. Версию выше для wine скачивать не рекомендую. Возможны проблемы с запуском и использованием.
На этом ресурсе все exe файлы является SFX архивами, т.е. что в Windows, что в Linux его можно распаковать как просто запустив, так и с помощью консольной утилиты 7z.
Из скачанного SFX архива нам нужен только сам Python. Остальные встроенные утилиты нас не интересуют. Поэтому, из скачанной версии распакуем только сам Python, а затем переместить эту папку по наиболее правильному, т.е. выгодному, пути с точки зрения управления переменными окружения PATH.
Все указанные ниже операции проделываются только для того, чтобы командная строка CMD или PowerShell могли видеть все EXE файлы внутри распакованной директории. Иначе вы не сможете ни запустить Python, ни управлять его PIP-ом.
Кстати, многие операции ниже можете проделать и вручную. Например, распаковку с помощью 7z-менеджера.
# Скачиваем портативную версию Python. Можете скачать с помощью браузера
mikl ~/003/Primer $ wget -O Portable-Python-3.8.9-x64.exe https://sourceforge.net/projects/portable-python/files/Portable%20Python%203.8/Portable%20Python-3.8.9%20x64.exe/download
# Создаем необходимые директории
mikl ~/003/Primer $ mkdir -p ~/.wine/drive_c/wsl-win-7/
# распаковываем из SFX архива только нужную папку с Python-ом
mikl ~/003/Primer $ 7z x Portable-Python-3.8.9-x64.exe -r "Portable Python-3.8.9 x64/App/Python/"
# Перемещаем папку с Python-ом без вложенных путей в нужную нам папку wsl-win-7 с переименованием
# Назвать все директории можете как угодно, главное без пробелов
mikl ~/003/Primer $ mv "./Portable Python-3.8.9 x64/App/Python/" ~/.wine/drive_c/wsl-win-7/Portable-Python-3.8.9-x64
# Удаляем ненужные полу-пустые директории
mikl ~/003/Primer $ rm -rf "./Portable Python-3.8.9 x64/"
Обратите внимание на создание пути «~/.wine/drive_c/wsl-win-7/».
«~/.wine/drive_c/»- это как раз и есть диск C: для wine.
В этом полном пути не должно быть никаких пробелов и символов запрещенных в именовании файлов и папок Windows.
Для себя я прописал дополнительную под-директорию по следующей причине. Вдруг мне понадобится вместо скачанной 64-битной версии ещё и 32-битная. И чтобы не загромождать диск C: папками и не разбираться потом что и зачем было скачано - я просто создам отдельную директорию. Если мне вдруг понадобится не только Python, но и например: make, cmake, mingw. Я просто также буду скачивать их и распаковывать по путям без пробелов в эту отдельную директорию.
Например:
- ~/.wine/drive_c/wsl-win-7/golang/golang-x86
- ~/.wine/drive_c/wsl-win-7/golang/golang-x64
- ~/.wine/drive_c/wsl-win-7/mingw/mingw-4.8.2-x86
- ~/.wine/drive_c/wsl-win-7/mingw/mingw-4.8.2-x64
При необходимости я просто удалю одну эту директорию и всё!
mikl ~/003/Primer $ rm -rf ~/.wine/drive_c/wsl-win-7/
Сейчас так делать не будем. Это просто пример.
Самое интересное здесь в том, что данный подход к использованию портативной версии Python работает не только в wine, но и в ОС Windows
Однако есть и ещё несколько нюансов использования любой ОС и любой версии Python-а.
В любом случае bat-файл будет служить в качестве запуска командной строки или PowerShell из текущей директории с добавлением путей к pip-у и самому Python-у в переменную PATH. И здесь необходимо обратить внимание на несколько моментов.
- Не все версии Python-а будут работать в ОС младше Windows 10
- Учитывайте, что командная строка в Windows 10 практически изжыла себя и работает не совсем адекватно. Её практически заменил Power Shell.
- В Windows 10 и старше не рекомендую скачивать и использовать и установочный и портативный вариант Python-а с официального сайта python.org - у них не работает pip как таковой. Почему не ясно. Лучше использовать с сайта sourceforge.net.
По крайней мере, мне запустить PIP так и не удалось. Даже с использованием и bootstrap-get-pip.py и github-get-pip.py.
Например, вот эти не рекомендуется скачивать и использовать.
Лучше заменить вот этими версиями. Да, сложнее ставить, зато pip точно будет работать.
Или вы можете собрать CPython вручную, используя mingw ( MinGW Toolchains targetting Win32, MinGW Toolchains targetting Win64 ), make и / или cmake sourceforge.net ( или cmake oficial ), распаковав или установив их все точно также, как и портативные версии выше по путям без пробелов и спец символов, а также прописав в запускаемом bat файле «SET PATH=;%PATH%» все пути к этим EXE-ам на разных строках, как и путь к исходному коду скачанной версии Python.
В случае сборки CPython вручную - что в Windows, что в Linux проблем с PIP-ом быть не должно. По крайней мере, у меня пока что, ни разу не возникало.
Для использования в Windows 10 всё что нужно, это заменить одну единственную строку в bat-файле.
cmd.exe на powershell.exe. Чуть ниже, вы это всё увидете.
После этого необходимо создать sh скрипт и расположить его в любом удобном для вас месте, а затем создать ссылку на него в /usr/bin/.
Создам отдельную директорию для всех скриптов: ~/programs/.
mikl ~/003/Primer $ mkdir -p ~/programs/
mikl ~/003/Primer $ touch ~/program/wine-cmd.sh && chmod +x ~/program/wine-cmd.sh
mikl ~/003/Primer $ nano ~/program/wine-cmd.sh
#!/bin/bash
wine '/home/mikl/.wine/drive_c/windows/system32/cmd.exe'
mikl ~/003/Primer $ sudo ln -s /home/mikl/program/wine-cmd.sh /usr/bin/wine-cmd
Осталось только создать bat-файл и готово - можно тестировать. Окончание строк файла удобнее и быстрее поменять на CR/LF с помщью Geany в следующем меню: Документ ► Установить окончание строк ► Заменить окончание строк на CR/LF (Windows).
Содержимое файла: cmd.bat.
mikl ~/003/Primer $ nano cmd.bat
@echo off
SET PATH=C:\wsl-win-7\Portable-Python-3.8.9-x64\;%PATH%
SET PATH=C:\wsl-win-7\Portable-Python-3.8.9-x64\Scripts\;%PATH%
cmd.exe
Команда «@echo off» не обязательна. Но с ней у вас не будет постоянно маячить перед глазами каждая выполняемая строка этого BAT-файла.
Команда «SET PATH=» обязательна. После равно обязательно через точку с запятой «;» указываем все необходимые пути. Заканчивать каждую такую строку обязательно «%PATH%».
Иначе вы потеряете доступ к CMD или PowerShell, а последний будет выдавать только ОШИБКИ вместо выполнения любой команды.
Вообще все пути «SET PATH=» можно расположить вообще в одной строке. Просто последовательно записать все пути через точку с запятой. Такой подход, как выше, реализован только для красоты и понимания что где находится. Просто вам же будет понятнее где какой путь находится и проще будет его подредактировать при необходимости, чтобы не искать в супер-длинной и не особо понятной строке.
Запустить всё можно следующей последовательностью комманд:
mikl ~/003/Primer $ wine-cmd
mikl ~/003/Primer $ cmd.bat
# После этого должен появится текст о версии продукта. Если не появился - значит что-то сделали не так или что-нибудь пропустили - читайте заново
Z:\home\mikl\003\Primer> python --version
Python 3.8.9
Теперь можно проверять Windows-Python код непосредственно в wine.
При необходимости - просто создавайте .bat файл с таким же содержимым в нужной вам директории и запускайте ваш Windows-Python код в той же описанной последовательности.
В Windows похожие .bat файлы используются для доступа либо к портативным версиям каких либо консольных программ, либо для того, чтобы не прописывать доступ к этим программам в переменные окружения самой системы.

Вам необходимо также знать, что в Windows 10 использование командной строки или PowerShell в режиме администратора несёт за собой несколько неприяных последствий. Рекомендуется запускать только от имени пользователя, т.е. двойным щелчком мыши по bat-файлу и всё.
При запуске в режиме администратора:
- При запуске вы всегда будете перемещены в C:\Windows\System32\ по умолчанию, чтобы бы вы не делали. cd не поможет
- Команды CD D: или cd C: не работают
- Для перемещения используйте, например, cd ../ для каталога выше
- SET PATH=C:\my-dir\;%PATH% - не работает. SET PATH... вообще не работает
Ну а в PowerShell соответственно не работают: $env:Path+=...
Т.е. для режима администратора все пути к вашим EXE программам всё-таки придётся записывать в переменные окружения самой системы.




В «Windows 7» изменение переменных окружения делается так.
Мой компьютер ► Свойства ► Дополнительные параметры системы ► Переменные среды ► PATH ► Изменить.
Затем через точку с запятой «;» прописываете любой необходимый вам путь.
Чтобы применить настройки - ОК, ОК, ОК...
Однако, более правильным будет немного другой подход.
В том же окне «Переменные среды» в разделе «Переменные среды пользователя для ...» Нажмите кнопку «Создать». Затем в поле Имя переменной дайте какое-нибудь имя без пробелов и знаков препинаний только латиницей. А в поле Значение укажите путь к нужному каталогу.
Нажмите ОК.
Затем «Path» ► Изменить ► и в открывшемся окне прописываете наименование только что созданной переменной.
В «Windows 10» это делается немного по другому.
WIN + R ► «control.exe» ► ОК ► (Просмотр ► Крупные значки. Не обязательно.) Система ► Дополнительные параметры системы ► Переменные среды ► PATH ► Изменить
Затем создайте необходимые вам пути.
Чтобы применить настройки - ОК, ОК, ОК...
Здесь тоже будет более правильным немного другой подход.
В том же окне «Переменные среды» в разделе «Переменные среды пользователя для ...» Нажмите кнопку «Создать». Затем в поле Имя переменной дайте какое-нибудь имя без пробелов и знаков препинаний только латиницей. А в поле Значение укажите путь к нужному каталогу.
Нажмите ОК.
Затем «Path» ► Изменить ► и в открывшемся окне создайте ещё один путь, указывая наименование только что созданной переменной.
Чтобы применить настройки - ОК, ОК, ОК...
А теперь об одном важном момент, о котором нигде не упоминается.
Если вы удалите какую либо программу, т.е. доступа к EXE файлам программы больше не будет - т.е. когда путь к программе будет больше не доступен - и при этом вы забудите удалить переменные окружения, которые добавляли по инструкции выше - то при любом запуске командной строки CMD или PowerShell - будут выдавать вам ошибки запуска - что не могут найти указанный путь и отказываться выполнять какие-либо команды.
При удалении программ, даже портативных - при добавлении переменных окружения, позаботьтесь и об их удалении.
Если ваши переменные окружения только внутри BAT файла - ничего нигде удалять не нужно!
Чтобы победить проблему сброса текущего расположения в режиме администратора в Windows-10 необходимо добавить в самое начало любого вашего bat-файла следующую строку:
@cd/d "%~dp0"
Данная команда никоим образом не мешает предыдущим версиям Windows.
Таким образом cmd.bat файл в итоге будет выглядеть следующим образом.
@cd/d "%~dp0"
@echo off
SET PATH=C:\wsl-win-7\Portable-Python-3.8.9-x64\;%PATH%
SET PATH=C:\wsl-win-7\Portable-Python-3.8.9-x64\Scripts\;%PATH%
cmd.exe
При этом абсолютно не имеет значения в какой системе вы используете запуск командной строки или PowerShell-а из BAT-файла для нужной версии Python-а: wine, Windows-7 или Windows-10.
Работать будет - везде одинаково!
Ну а сегодня на этом всё. Всем Добра и Удачи!
Copyright © 04.08.2022 by Mikhail Artamonov