
Random на службе сисадмина
Оглавление
В процессе работы со случайными числами нам понадобится 2 дополнительных пакета: bc и xxd.
Для исключения непредвиденных ошибок терминала, все команды рекомендуется выполнять в Bash.
Наливайте приятную для вас жидкость, усаживайтесь поудобнее. А мы начинаем ...
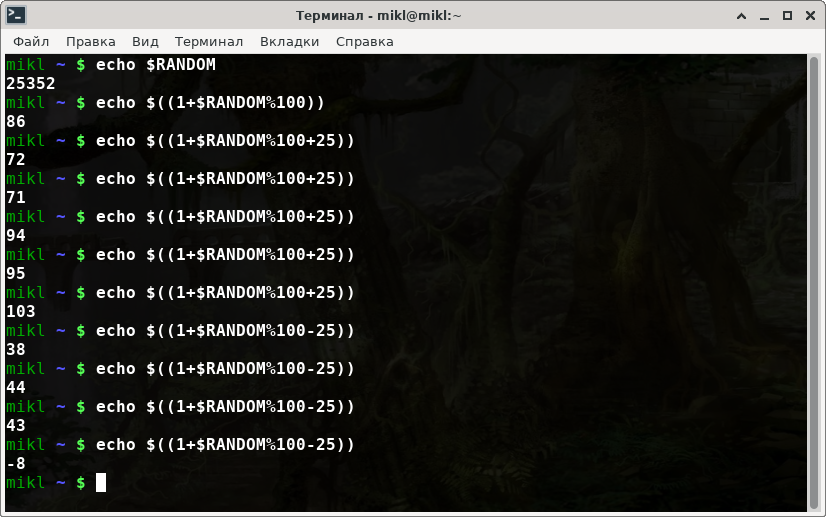
Для генерации случайного числа используется $RANDOM. А мы можем сгенерировать числов диапазоне, например от 0 до 100 ?
Конечно, можем
$ echo $((0+$RANDOM%100)) # 0 - число ОТ, 100 - число ДО
На скриншоте вы можете видеть как скорретировать диапазон генерации псевдослучайного числа.
Хорошо. А мы можем сгенерировать случайное имя. Ответ - да, можем.
Можно воспользоваться следующими командами:
# Linux $ cat /dev/urandom | tr -cd 'a-f0-9' | head -c 32 # OS X или другой BSD $ cat /dev/urandom | env LC_CTYPE=C tr -cd 'a-f0-9' | head -c 32
Можно воспользоваться unix mktemp:
$ TMPFILE=`mktemp tmp.XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX` && echo $TMPFILE tmp.PwowNsqK6yiHzSP4wB1meJvnzErQacI6
Но куда интереснее поработать с именами через RANDOM. Т.к. в этом случае мы сможем понять как преобразуются символы в числа и обратно, а также диапазон алфавита Unicode. Именно для этого и понадобятся 2 дополнительных утилиты - basic calculator (bc) и xxd.
xxd грубо говоря, преобрузет строку в шестнадцатеричный код или обратно из шестнадцатеричного кода в строку.
# Из строки в шестнадцатеричный формат HEX $ echo -e -n "string" | xxd -p | tr [:lower:] [:upper:] # tr преобразует символы нижнего регистра в верхний для дальнейшего использования в разных утилитах # Из шестнадцатеричного формата в строку echo -e -n "hex" | xxd -r -p
У bc есть одна меленькая особенность. Работая с шестнадцатеричной системой счисления ему обязательно нужен верхний регистр символов, иначе он выдаст ошибку синтаксиса.
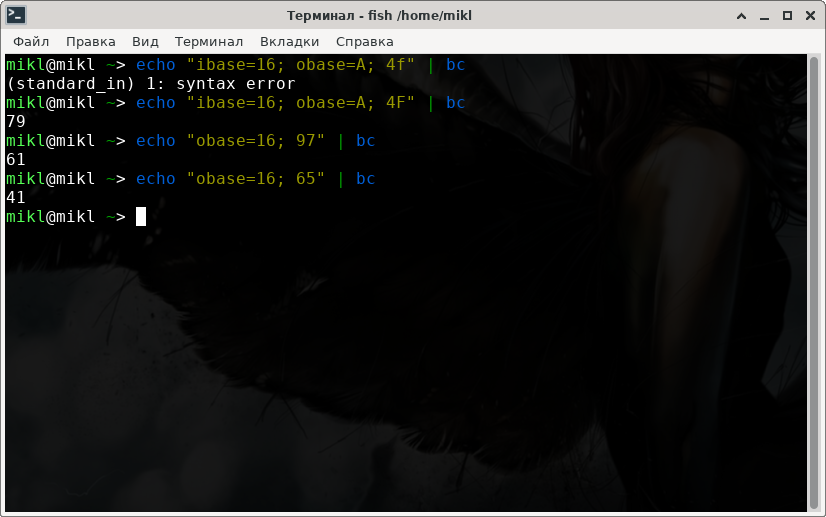
Диапазон английского алфавита в Unicode для верхнего регистра символов находится в диапазоне от 65 до 90 в десятичной системе счисления и для нижнего регистра символов в десятичной системе счисления в диапазоне от 97 до 122. В Шестнадцатеричной соответственно для верхнего от 41 до 5A и для нижнего от 61 до 7A.
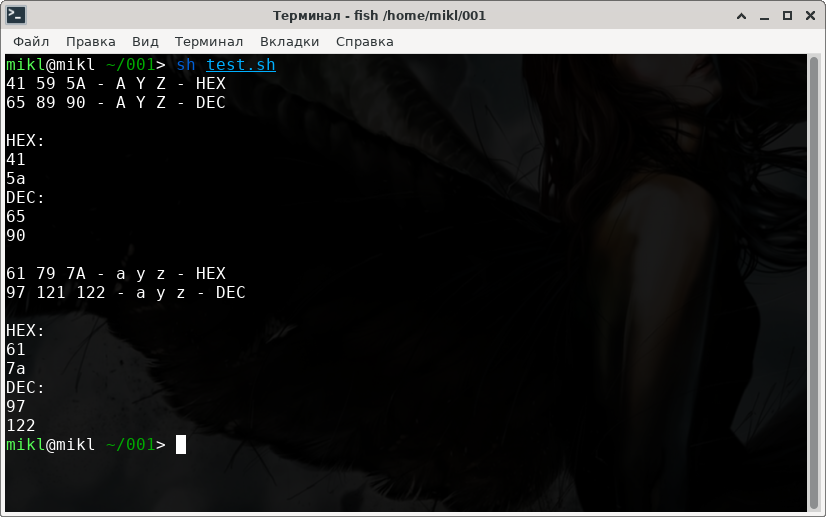
Проверяем ...
#!/bin/bash echo -e -n "41 59 5A - A Y Z - HEX\n65 89 90 - A Y Z - DEC\n" echo "" echo "HEX:" echo -e -n "A" | xxd -p echo -e -n "Z" | xxd -p echo "DEC:" echo "ibase=16;obase=A;41" | bc echo "ibase=16;obase=A;5A" | bc echo "" echo -e -n "61 79 7A - a y z - HEX\n97 121 122 - a y z - DEC\n" echo "" echo "HEX:" echo -e -n "a" | xxd -p echo -e -n "z" | xxd -p echo "DEC:" echo "ibase=16;obase=A;61" | bc echo "ibase=16;obase=A;7A" | bc
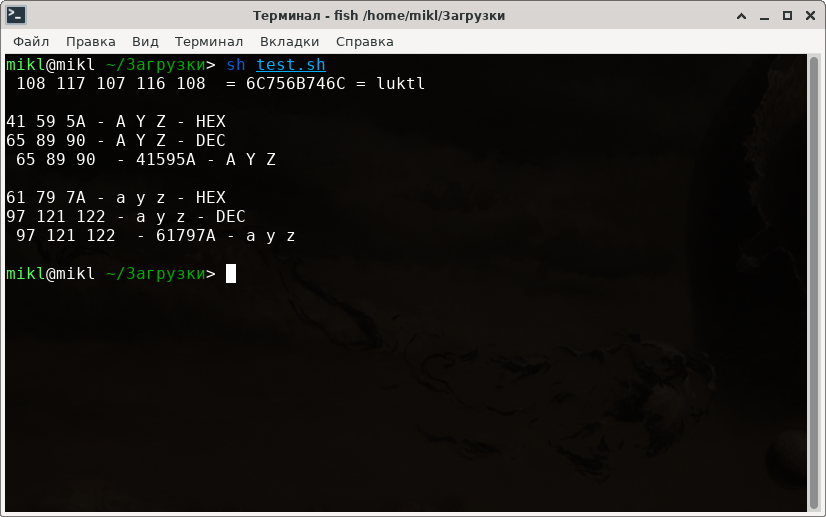
Хотелось бы немного быстрее - автоматическую генерацию, а также обратное преобразование текста в десятичные числа.
Не вопрос. Сказано, сделано ... 😀 😎
Чтобы преобразования были верными обратите внимание на несколько важных моментов, часть из которых вы уже знаете.
- Для утитилы bc шестнадцатеричные коды должны быть в верхнем регистре.
- Чтобы преобразовывать HEX коды в символы верно необходимо входную строку HEX символов обрабатывать по частям, т.е. раздельно по 2 символа за один раз.
- Для каждой буквы должно генерироваться отдельное псеводслучайное число.
- Преобразовывать в одной строке регистры символов и тут же передавать строку по конвееру утилите bc не самая удачная идея! Иначе может возникнуть та же ситуация как с ошибкой синтаксиса.
- Строка начинается от 0. Утилита wc последний символ конца строки, также считает его за символ. Утилита awk не обращает на это внимание.
- При преобразовании из 16 в 10 систему счисления для obase не забывайте ставить A, а не 10.
#!/bin/bash function ord() { echo -e -n "$@" | xxd -p | tr [:lower:] [:upper:] } function chr() { echo -e -n "$@" | xxd -r -p } function hex_to_count() { in_str="${1}" declare -a out_str temp="" count=$(echo "${1}" | awk '{print length}') for (( i=0; i<=${count}; i+=2 )); do temp=$(echo "${in_str:$i:2}" | tr [:lower:] [:upper:]) dec_count=$(echo "ibase=16;obase=A;${temp}" | bc) out_str=("${out_str[*]}" "$dec_count") done echo "${out_str[*]}" } function gen_rand_hex() { # echo "ibase=16; 61" | bc # 65 # echo "obase=16; 26" | bc # 1A # ord "AYZ" # ord "ayz" # 41 59 5A - A Y Z - HEX # 65 89 90 - A Y Z - DEC # 61 79 7A - a y z - HEX # 97 121 122 - a y z - DEC # 65...122 - DEC rez_str="" cnt=1 declare -i count count=$1 while [ $cnt -le $count ]; do rnd_count=$(echo $((1 + RANDOM % 25 + 97))) hex_count=$( echo "obase=16; ${rnd_count[*]}" | bc ) rez_str="${rez_str}${hex_count}" let cnt+=1 done echo "${rez_str[*]}" } rand_hex=$(gen_rand_hex "5") dec_str=$(hex_to_count "$rand_hex") rez_str=$(chr "${rand_hex}") echo "${dec_str} = ${rand_hex} = ${rez_str}" echo "" # echo "41 59 5A - A Y Z - HEX" echo "65 89 90 - A Y Z - DEC" # my_str="AYZ" hex_my_str=$(ord "$my_str") dec_my_str=$(hex_to_count "${hex_my_str}") echo "${dec_my_str} - ${hex_my_str} - A Y Z" echo "" # echo "61 79 7A - a y z - HEX" echo "97 121 122 - a y z - DEC" # my_str="ayz" hex_my_str=$(ord "$my_str") dec_my_str=$(hex_to_count "${hex_my_str}") echo "${dec_my_str} - ${hex_my_str} - a y z" echo "" # exit 0
Ну а на этом на сегодня всё. Моё дело - лишь заинтересовать вас.
Copyright © 07.07.2021 by Mikhail Artamonov